
【チュートリアル #1】深層学習を使った競馬予想AI作成¶
0-1.本講座の目的¶
深層学習を使った競馬予想AIの作成方法を本講座で解説していきます。
本講座を通して、PyTorchを使った競馬予想AIの深層学習モデルを自力で作れるようになることを目的としています。
まずは、深層学習の基本をおさえるため、
本Notebookでは、深層学習とは何者なのかといったところを取り上げるチュートリアル的な位置づけである。
本チュートリアルで扱う項目は以下
- 深層学習の基本的な知識:今回の内容
- 深層学習の学習過程:今回の内容
- データセット作成
- PyTorchのモデル構築方法
- 学習・推論の実行
- モデルの解釈方法
- モデル保存
0-2.なぜ深層学習?¶
我々は儲かる競馬AI作成を最終目標として本シリーズを進めてきました。
これまでの「ゼロから作る競馬予想モデル・機械学習入門」バージョン1ではLightGBMをベースとした競馬予想AI作成の解説をしており、LightGBMの欠点を考慮した特徴量の追加方法や目的関数の自作(カスタムObject)による性能改善のやり方などを取り上げてきました。
そういった中でLightGBMを使った競馬AI作成を通してえられた課題が2つありました。
- LightGBMでは学習できるモデルのバリエーションが少ない
最終目標である儲けが出せる競馬AIを作成するためにはオッズを考慮した学習が必要不可欠だが、LightGBMベースの競馬AIを作成する場合オッズを考慮できるデフォルトのObject関数がほぼなく、自作のObject関数を用意する必要がある。
LightGBMの実装上、カスタムObjectもC++での実装が必要になりC++の基本的な文法理解、LightGBMでどのようにカスタムObjectが使われるのか、受け取った引数の扱い方はどうなのか等の調査が必要となり、学習コストがかなり高い。(調べた感じあまりそういうことやってる人が少ない) - オッズの流動性
これまで作成したファーストモデル~サードモデルではオッズを何かしらの形で使うようなモデルになっていたが、このときに使っていたオッズはすべて最終オッズとなっている。
最終オッズとはレースの着順が決定してから払戻金が決定した段階で決まる値となっているため、通常レース予測時点では知ることができない情報となっている。
これまでは使用するオッズは理想的なオッズであるというゆるふわな前提を置いており、厳密な競馬AIと呼ぶには不適切だった。
これらの課題を解決するには以下のような方針がある
- 目的関数のカスタムのしやすさ
LightGBMではC++による実装が必要なため、時間的なコストが高いことから目的関数の自作がやりやすいアーキテクチャが求められる - オッズの推定モデルの作成
最終オッズしか情報として持っておらず、レース前の暫定オッズの情報の入手が困難な以上オッズの推定を行うモデルの作成が必要不可欠である。
またそうなった場合、オッズの推定+儲かるAIの作成という2つのタスクを学習する必要がある。
オッズの推定と儲かるAI別々にモデルを作成するのであれば、LightGBMでも実現可能ではあるが、一般的に1つのモデルで2つのタスクを同時に学習する方が良いものになりやすいので、複数タスクを同時に学習できるモデルが理想である。
よって、これらの対応方針を実現するには、PyTorchを使った深層学習モデルの作成が最も有用であると考えたため、LightGBMではなく深層学習を使ったAI作成に取り組むこととした。
0-3.前提環境¶
使用する深層学習ライブラリの紹介です。
- Python 3.10.5
- PyTorch 2.3.1
- GPU使う場合は:CUDA 18
ない場合はpip等でインストールしてください。
0-4.宣伝(環境準備)¶
本講座で扱うソースでは一部秘匿させていただいております。
ソースは「ゼロから作る競馬予想モデル・機械学習入門」にあるものを使用しています。
また、本Notebookは「dev-um-ai > notebook > DeepLearning > 0000_deeplearning_tutrial.ipynb」にあります。
環境構築(パッケージ管理)はpoetryを使用しているので、プロジェクトファイルさえあればコマンド一発で環境構築が完了するので、ぜひご活用ください。
Bookersアカウントとご自身のYouTubeアカウントを連携していただき、以下のチャンネルを登録して頂きますと1000円引きで入手出来ますのでぜひ登録よろしくお願いいたします。

1.深層学習の基本的な知識¶
深層学習を実装する際に考慮するべき最低限の構成要素には、以下のようなポイントが含まれます。
1. データ準備¶
- データの収集と前処理: データの質がモデルの性能に大きく影響するため、適切なデータを収集し、欠損値の処理、正規化、データの拡張などを行うことが重要です。
- データの分割: 学習データ、検証データ、テストデータに分割することで、モデルの汎化性能を正確に評価できます。
2. モデルの設計¶
- モデルのアーキテクチャ: ニューラルネットワークの層数、各層のノード数、活性化関数などを選択する必要があります。例えば、画像認識ではCNN、自然言語処理ではRNNなどが使われます。
- ハイパーパラメータ: 学習率、バッチサイズ、エポック数などのハイパーパラメータを適切に設定することが重要です。
3. 損失関数の作成¶
- モデルが目指すべき目標に基づいて、適切な損失関数を選択します。例えば、分類問題ではクロスエントロピー損失、回帰問題では平均二乗誤差が一般的に使われます。
4. オプティマイザの選定¶
- 学習の進め方を制御するオプティマイザも重要な構成要素です。SGDやAdam、RMSpropなど、タスクに応じて最適なオプティマイザを選択します。
5. モデルの学習と評価¶
- 学習プロセス: ミニバッチを使用した反復学習や、エポックごとの損失の監視を行います。
- 評価指標: モデルの性能を測るために、正確性(Accuracy)、F1スコア、RMSEなど、タスクに適した評価指標を選択します。
以上の要素は全てPyTorchを使って実装することができます。
オプティマイザの選定や学習などは、決まったものがあるので基本的にはその辺に落ちてるサンプルを使えばOKだと思います。
問題なのが、データ準備とモデルの設計と損失関数の作成が最も手を動かすべきところでかつ色々と壁にぶつかる場所です。
基本的にこれらの項目はすべて自作する必要があるので、カスタマイズ性が高い一方で何をどうすれば良いか分からないことが多いので、そういったところを本講座ではサポートできればと考えています。
2.深層学習の仕組み¶
深層学習は何をしているのか?を図を使って説明する
深層学習の中身というのは、モデルの設計で構築するモデルのことである。
簡略化のために以下のようなモデル構造を例に深層学習の学習過程を見ていく
モデル構造¶
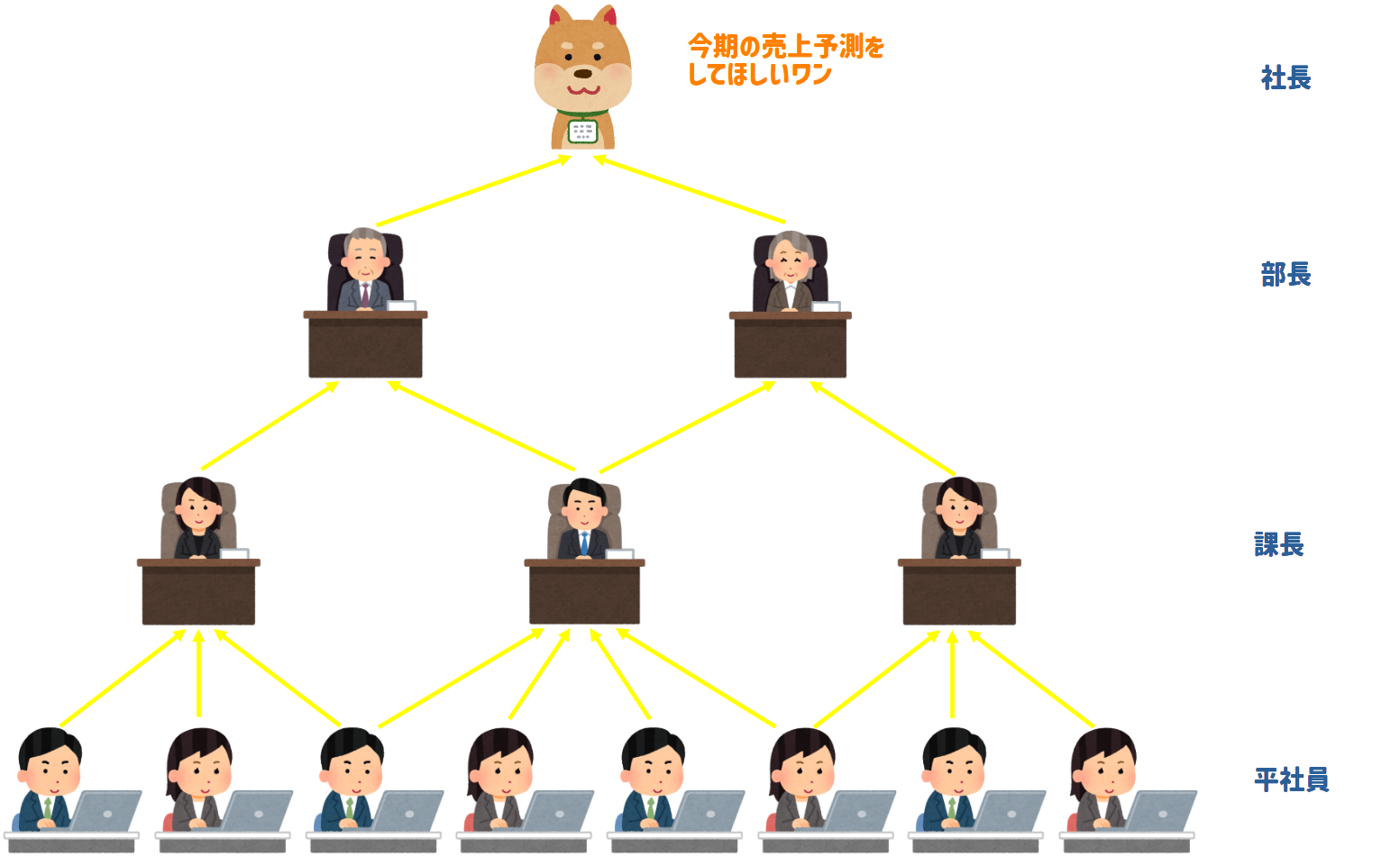
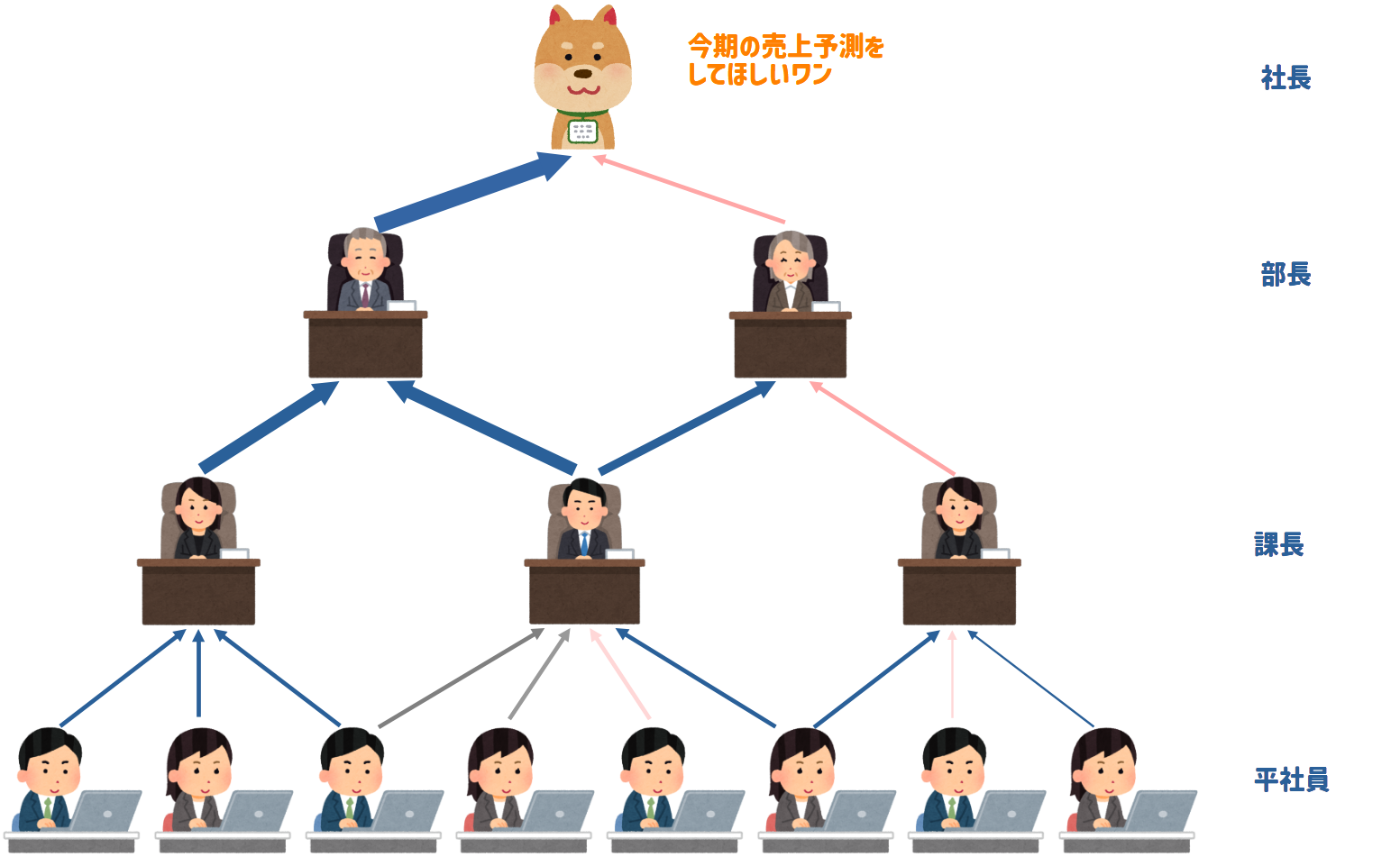
この図では、犬社長が「今期の売上予測」というタスクを持っており、下層にいる社員たちはそのタスクを解決するために雇われている3階層の組織構造になっているとします。
このとき、一番下にいる平社員たちを深層学習では「入力層」、課長や社長たちを「隠れ層」「中間層」、最後の社長を「出力層」と言います。
また、犬社長も含めてこの社員一人一人のことをノードと呼びます。
データの流れ¶
上記のモデル構造では受け取ったデータがどうなって犬社長のタスク解決に繋がるのか見ていきましょう
Step1:データ入力¶
犬社長から今期の売上予測をしてくれと下命があったため、平社員たちは業務実績の情報を元に売上を見積もります
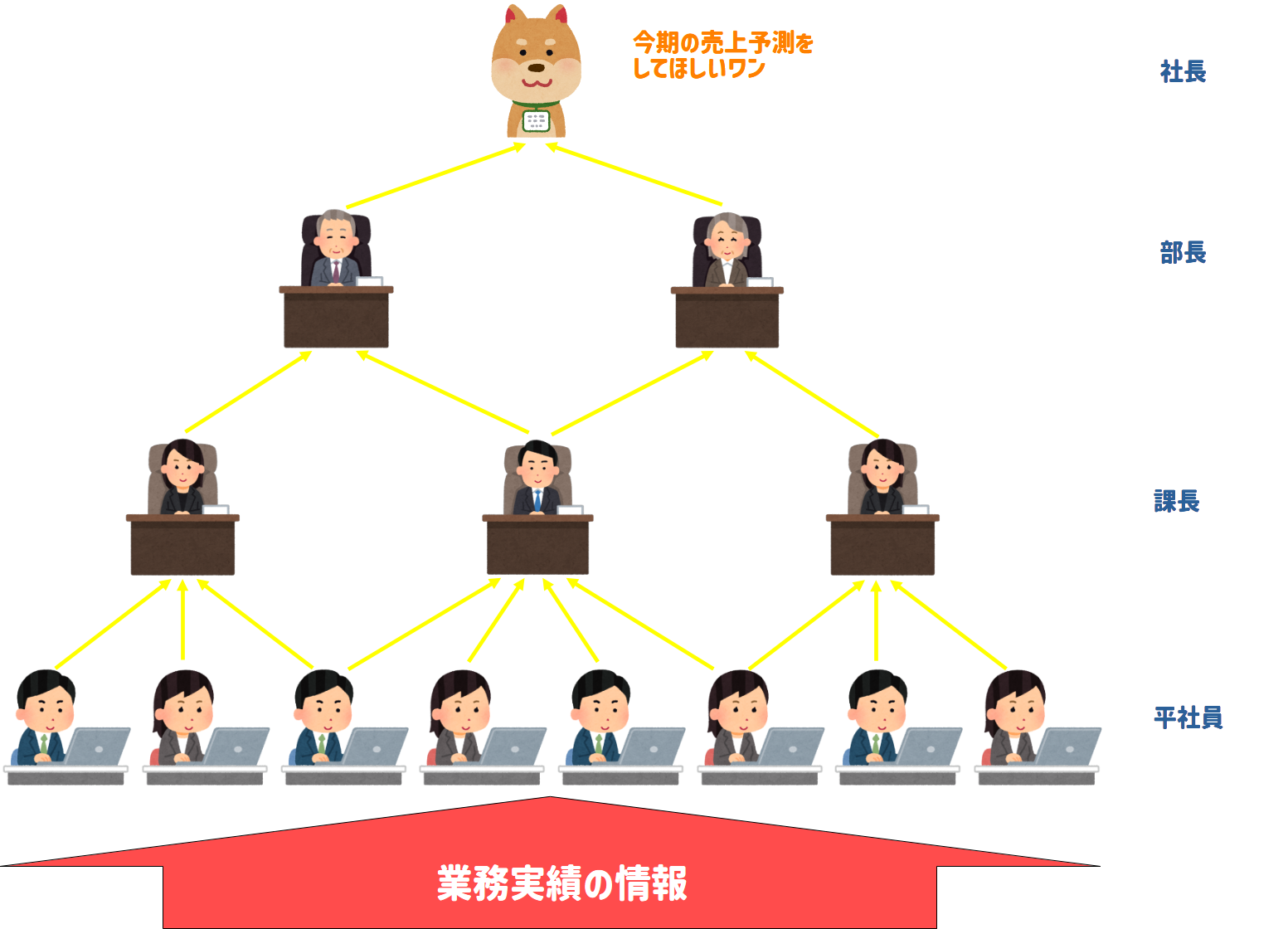
Step2:平社員(入力層)評価¶
業務実績の情報から、平社員たちは課長へ見積もり結果を共有します。
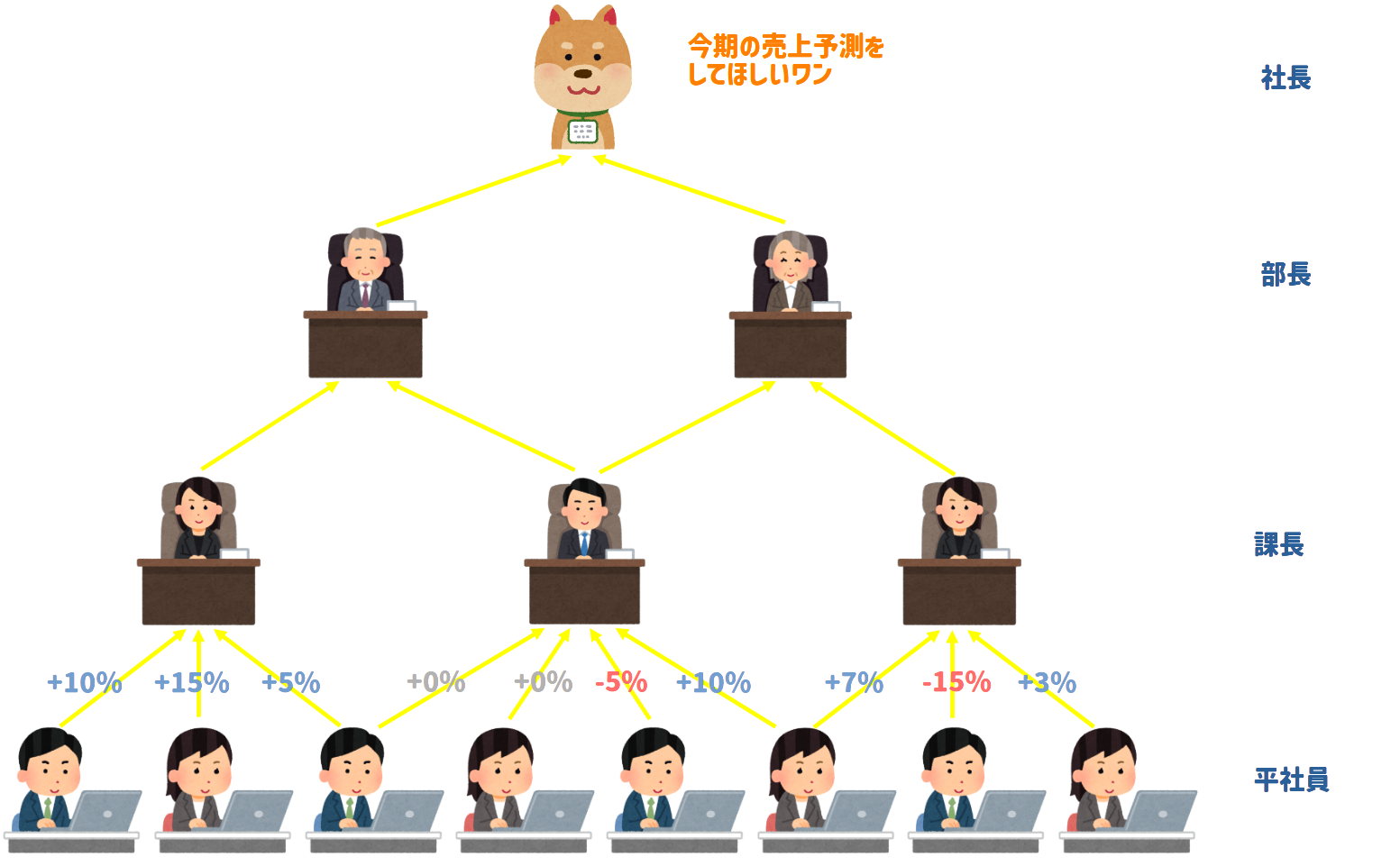
Step3:部課長(隠れ層)評価¶
平社員たちの報告を受けて、部課長もそれぞれの評価基準で見積もりを上に送ります
Step4:社長(出力層)評価¶
部長たちの評価を受けて犬社長が今期の売上予測を行います

上記のStep1からStep4までのデータの流れ方は順伝播と言われています
損失の評価¶
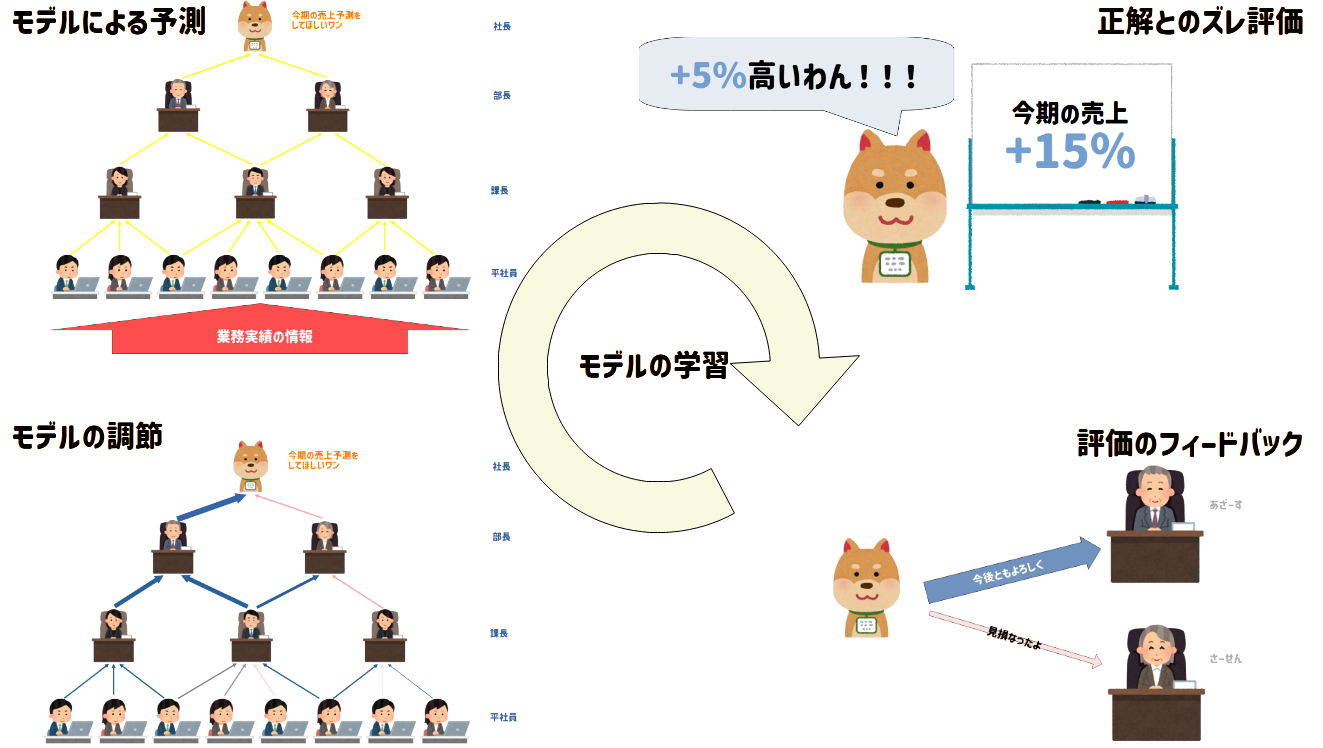
ここでは、モデルが出した予測と実際のデータとの違いを評価し、モデル全体の評価を改める過程を見ていきます。
犬社長は業務実績から社員たちが算出した予測をもとに全体の売上予測を+10%と予測しました。
この予測があっているかどうか確かめるべく、期末で売りあがった業績の結果と比べてみたところ、実際の売上が+15%であることが分かりました。
この実際の売上のことを「教師データ」、犬社長の予測結果を「予測値」と言います
損失の計算¶
モデルは自分が予測した値と教師データの値を見比べて、どのくらい間違っているかを評価してモデルのノードへフィードバックしていきます。
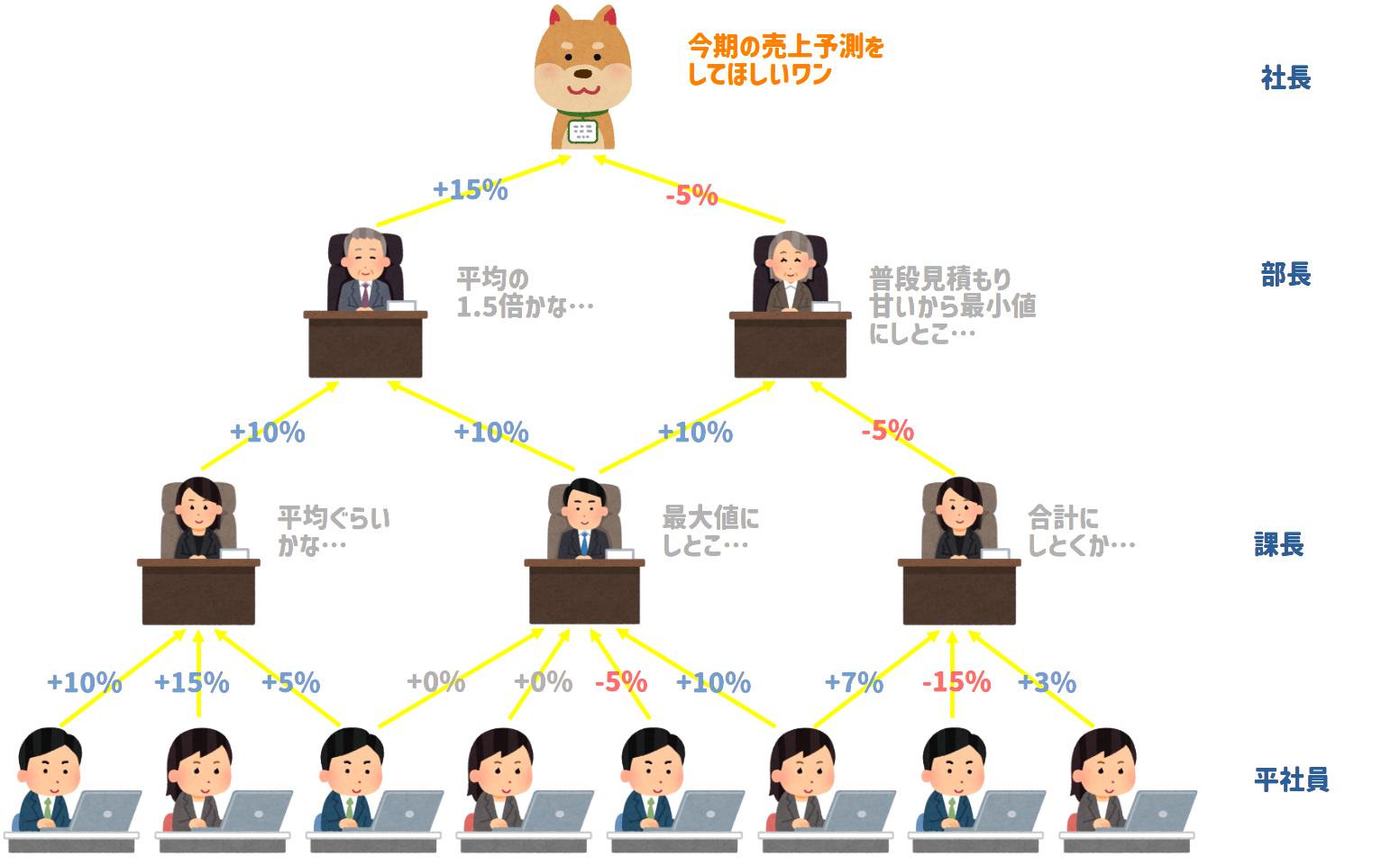
今回の組織図で言うと犬社長が出した予測結果と実際の結果に5%の乖離が生じていることが分かりました。

そこで、犬社長はこの5%のずれを解消するために、直下にいる社員である部長Aと部長Bにフィードバックを送ります。

この教師データと予測値の違いを評価するものを「損失関数」と呼びます。損失関数には様々な種類があり、解きたいタスクに応じて選択すると良いでしょう。
PyTorchにも備え付けの損失関数がありますが、カスタマイズすることもでき、LightGBMと比して格段にやりやすいです。
損失のフィードバック¶
今回の予測は、犬社長にとって部長Aの見積もりが正確で、部長Bの見積もりが不正確だと評価します。
このとき、犬社長は今後も同じように売上の予測がしたい場合、部長Bよりも部長Aの見積もりに重きを置くようになります。
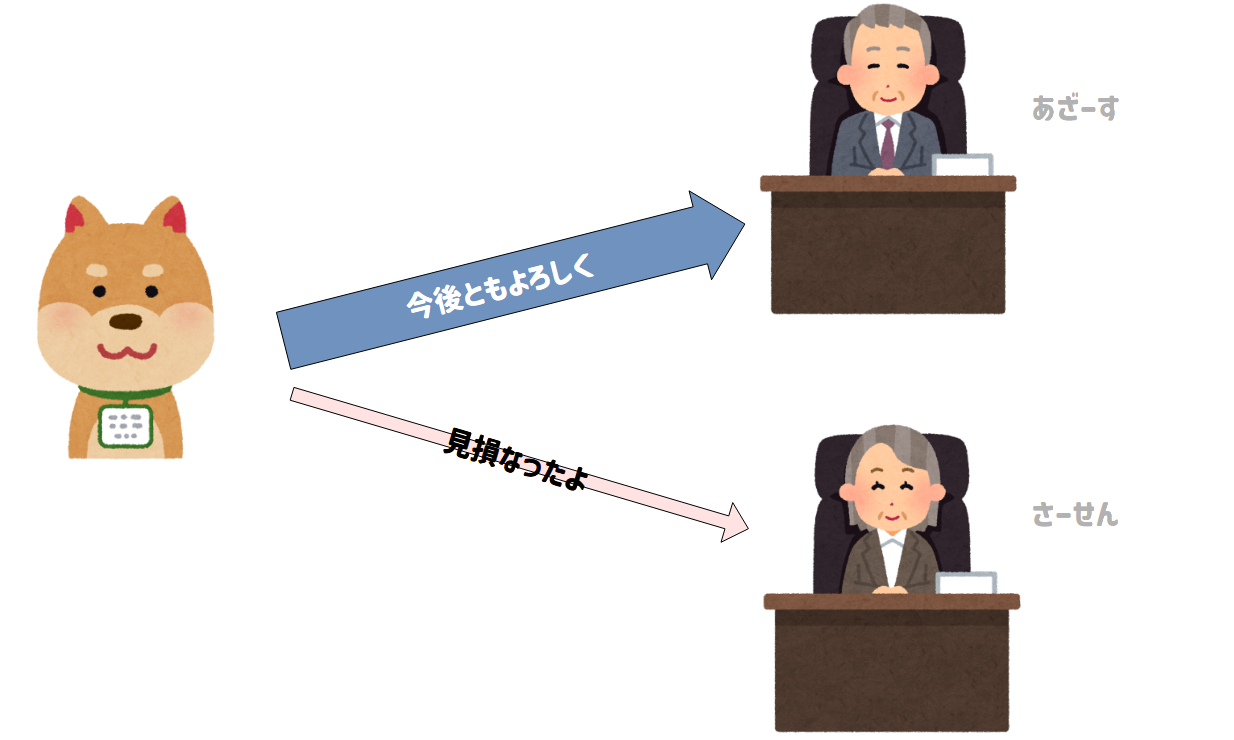
部長たちは犬社長から受け取った評価をさらに下の課長へ、課長は平社員へフィードバックを送ります。
フィードバックが全体にいきわたると、下の組織図のように上手に見積もりが取れた社員とのつながりを強化して、そうでない社員とのつながりを薄くした組織図が出来上がります。
以上のような、正解の値と予測値のズレを評価し、そのズレを元にノードごとのつながりの濃淡を調整するようにフィードバックしていくことを「逆伝播」と言います
3.次回¶
次回は、実際にPyTorchを使った競馬AIの作り方の手順を解説していきます。
まずは動くものを作りたいので、モデルの構造は非常に簡単なものにして入口に必要なデータと出口のデータの形をどうするかを確認していきます。



コメント