はじめに¶
私は競馬予想AIの開発をしています。動画で制作過程の解説をしています。良ければ見ていってください。

また、共有するソースの一部は有料のものを使ってます。
同じように分析したい方は、以下の記事から入手ください。

9.過去成績から上り3Fの予測
前回は話では、脚質と持ちタイムの情報から上り3Fに到達するまでの走破タイムの予測可能性を話した。
今回は、残りの上り3Fの走破タイムの予測が可能かどうかを確認する
9-1.上り3Fの予測がしたい理由
前回の話ではレース結果の上り3Fのタイムを除いた走破タイムをLightGBMの回帰モデルで予測できそうだと分かった。
前回の話↓

そのため、上り3Fの予測タイムの算出が出来れば、ラストスパートで足が残っているかどうかの判断が出来るのではという期待から、上り3Fの予測をしたいと考えた。
9-2.データ準備
ソースの一部は有料のものを使ってます。
同じように分析したい方は、以下の記事から入手ください。
まずは、前回のLightGBMのモデル作成で使用したデータの作成まで行う
import pathlib
import warnings
import lightgbm as lgbm
import pandas as pd
import tqdm
import datetime
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import numpy as np
import sys
sys.path.append(".")
sys.path.append("..")
from src.data_manager.preprocess_tools import DataPreProcessor # noqa
from src.data_manager.data_loader import DataLoader # noqa
warnings.filterwarnings("ignore")
root_dir = pathlib.Path(".").absolute().parent
dbpath = root_dir / "data" / "keibadata.db"
start_year = 2000 # DBが持つ最古の年を指定
split_year = 2014 # 学習対象期間の開始年を指定
target_year = 2019 # テスト対象期間の開始年を指定
end_year = 2023 # テスト対象期間の終了年を指定 (当然DBに対象年のデータがあること)
# 各種インスタンスの作成
data_loader = DataLoader(
start_year,
end_year,
dbpath=dbpath # dbpathは各種環境に合わせてパスを指定してください。絶対パス推奨
)
dataPreP = DataPreProcessor()
df = data_loader.load_racedata()
dfblood = data_loader.load_horseblood()
df = dataPreP.exec_pipeline(
df, dfblood, ["s", "b", "bs", "bbs", "ss", "sss", "ssss", "bbbs"])
持ちタイムの計算
targetCol = "toL3F_vel"
idf = df.copy()
idf = idf[~idf["horseId"].isin(
idf[idf["horseId"].str[:4] < "1998"]["horseId"].unique())]
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance", "age"])[
targetCol].shift()
idf["mochiTime"] = idf.groupby(['horseId', "field", "distance", "age"])["mochiTime_org"].rolling(
1000, min_periods=1).max().reset_index(level=[0, 1, 2, 3], drop=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance"])[
targetCol].shift()
idf["mochiTime"].fillna(idf.groupby(['horseId', "field", "distance"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "dist_cat"])[
targetCol].shift()
idf["mochiTime"].fillna(idf.groupby(['horseId', "field", "dist_cat"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field",])[
targetCol].shift()
idf["mochiTime"].fillna(idf.groupby(['horseId', "field"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1], drop=True), inplace=True)
targetCol = "last3F_vel"
idf = idf[~idf["horseId"].isin(
idf[idf["horseId"].str[:4] < "1998"]["horseId"].unique())]
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance", "age"])[
targetCol].shift()
idf["mochiTime3F"] = idf.groupby(['horseId', "field", "distance", "age"])["mochiTime_org"].rolling(
1000, min_periods=1).max().reset_index(level=[0, 1, 2, 3], drop=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance"])[
targetCol].shift()
idf["mochiTime3F"].fillna(idf.groupby(['horseId', "field", "distance"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "dist_cat"])[
targetCol].shift()
idf["mochiTime3F"].fillna(idf.groupby(['horseId', "field", "dist_cat"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field",])[
targetCol].shift()
idf["mochiTime3F"].fillna(idf.groupby(['horseId', "field"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1], drop=True), inplace=True)
targetCol = "last3F_vel"
idf = idf[~idf["horseId"].isin(
idf[idf["horseId"].str[:4] < "1998"]["horseId"].unique())]
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance", "age"])[
targetCol].shift()
idf["mochiTimeDiff"] = idf.groupby(['horseId', "field", "distance", "age"])["mochiTime_org"].rolling(
1000, min_periods=1).mean().reset_index(level=[0, 1, 2, 3], drop=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "distance"])[
targetCol].shift()
idf["mochiTimeDiff"].fillna(idf.groupby(['horseId', "field", "distance"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field", "dist_cat"])[
targetCol].shift()
idf["mochiTimeDiff"].fillna(idf.groupby(['horseId', "field", "dist_cat"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1, 2], drop=True), inplace=True)
idf["mochiTime_org"] = idf.groupby(['horseId', "field",])[
targetCol].shift()
idf["mochiTimeDiff"].fillna(idf.groupby(['horseId', "field"])["mochiTime_org"].rolling(
1000, min_periods=1).min().reset_index(level=[0, 1], drop=True), inplace=True)
ペース情報の算出
idfpace = idf.drop_duplicates(
"raceId", ignore_index=True) # 処理しやすいように重複を削除しておく
idfpace[["raceId", "rapTime"]]
idfpace["rapTime2"] = idfpace[["rapTime", "distance"]].apply(
lambda row: row["rapTime"] if row["distance"] % 200 == 0
else [round(row["rapTime"][0]*200/(row["distance"] % 200), 1)] + row["rapTime"][1:], axis=1)
idfpace[idfpace["distance"].isin([1150])][["rapTime", "rapTime2"]]
idfpace["prePace"] = idfpace["rapTime2"].apply(
lambda lst: np.mean(lst[:(len(lst)-3)//2]))
idfpace["pastPace"] = idfpace["rapTime2"].apply(
lambda lst: np.mean(lst[(len(lst)-3)//2:-3]))
idfpace["prePace3F"] = idfpace["rapTime2"].apply(
lambda lst: np.mean(lst[:-3]))
idfpace["pastPace3F"] = idfpace["rapTime2"].apply(
lambda lst: np.mean(lst[-3:]))
idfpace[["raceId", "rapTime2", "prePace", "pastPace"]]
レース出走馬の持ちタイムの平均値の計算
idfvel = idf.groupby("raceId")[
["last3F_vel", "toL3F_vel", "velocity", "mochiTime", "mochiTime3F"]].mean().rename(columns=lambda x: f"{x}_mean").reset_index()
idfvel = pd.merge(idfpace[[
"raceId", "prePace", "prePace3F", "pastPace", "pastPace3F",]], idfvel, on="raceId")
idfvel.corr().loc[["mochiTime_mean", "mochiTime3F_mean"]]
結果から出走馬の持ちタイムの平均値であるmochiTime_meanに対してpastPace3F, pastPace, toL3F_vel_meanで0.8の相関がある。
つまり、出走馬の持ちタイム(速度指標)が速くなると後半のペース情報であるpastPaceが早くなり、出走馬の上り3Fに至るまでの速度の平均であるtoL3F_vel_meanが速くなることを意味する。
先では出走馬の平均情報とペース情報の関係をみた。
つぎは、各馬の持ちタイムと前走でのvelocity, last3F_vel, toL3F_velとレース結果のvelocity, last3F_vel, toL3F_velとの相関を確認する。
idf["vel_lag1"] = idf.groupby("horseId")["velocity"].shift()
idf["l3Fvel_lag1"] = idf.groupby("horseId")["last3F_vel"].shift()
idf["t3Fvel_lag1"] = idf.groupby("horseId")["toL3F_vel"].shift()
idf[["velocity", "last3F_vel", "toL3F_vel", "vel_lag1",
"l3Fvel_lag1", "t3Fvel_lag1", "mochiTime", "mochiTime3F"]].corr().loc[
["vel_lag1", "l3Fvel_lag1", "t3Fvel_lag1", "mochiTime", "mochiTime3F"]][["velocity", "last3F_vel", "toL3F_vel"]]
idfp = pd.merge(
idf[["raceId",]+list(set(idf.columns) - set(idfvel.columns))],
idfvel[["raceId", "last3F_vel_mean", "toL3F_vel_mean",
"mochiTime_mean", "mochiTime3F_mean"]],
on="raceId"
)
idfp
持ちタイムの平均値との差を計算
idfp["mochiTime_diff"] = idfp["mochiTime"] - idfp["mochiTime_mean"]
idfp["mochiTime3F_diff"] = idfp["mochiTime3F"] - idfp["mochiTime3F_mean"]
idfp["last3F_diff"] = idfp["last3F_vel"] - idfp["last3F_vel_mean"]
idfp["toL3F_diff"] = idfp["toL3F_vel"] - idfp["toL3F_vel_mean"]
idfp[["last3F_diff", "toL3F_diff", "mochiTime_diff", "mochiTime3F_diff"]].corr(
).loc[["mochiTime_diff", "mochiTime3F_diff"]][["last3F_diff", "toL3F_diff"]]
脚質情報の追加
from sklearn.cluster import KMeans # KMeans法のモジュールをインポート
for col in ["label_1C", "label_lastC"]:
idfp[f"{col}_rate"] = (idfp[col].astype(
int)/idfp["horseNum"]).convert_dtypes()
# クラスタ数
n_cls = 4
rate = 2.5
# クラスタリングする特徴量を選定
cluster_columns = ["label_1C_rate", "label_lastC_rate"]
cluster_columns2 = ["label_1C_rate", "label_lastC_rate2"]
kmeans = KMeans(n_clusters=n_cls) # 脚質が4種類なので、クラス数を4とする
idfp["label_lastC_rate2"] = rate*idfp["label_lastC_rate"]
# 後でクラスタ中心を振り直すが、形式上一旦fitしておかないといけない。
kmeans.fit(idfp[cluster_columns2].iloc[:n_cls*2])
# クラスタ中心をセット
centers = [
[0.189736, 0.393819],
[0.432436, 0.995918],
[0.639462, 1.612348],
[0.836256, 2.227643]
]
kmeans.cluster_centers_ = np.array(centers)
# 脚質の分類
idfp["cluster"] = kmeans.predict(idfp[cluster_columns2])
# 名前も付けておく
clsnames = ["逃げ", "先行", "差し", "追込"]
cls_map = {i: d for i, d in enumerate(clsnames)}
idfp["clsName"] = idfp["cluster"].map(cls_map)
idfp["clsName"].value_counts().to_frame().T
ペース情報の追加
idf = pd.merge(idfp, idfpace[["raceId", "prePace",
"pastPace", "prePace3F", "pastPace3F"]], on="raceId")
過去の脚質情報の追加
for lag in range(1, 11):
idf[f"clsName_lag{lag}"] = idf.sort_values("raceDate").groupby("horseId")[
"clsName"].shift(lag)
過去の上り3F速度と上り3F到達時速度との差の追加
idf["l3F_diff"] = 200*60/idf["last3F_vel"] - 200*60/idf["toL3F_vel"]
for lag in range(1, 11):
idf[f"l3Fdiff_lag{lag}"] = idf.sort_values("raceDate").groupby("horseId")[
"l3F_diff"].shift(lag)
lagcolumns2 = [f"l3Fdiff_lag{lag}" for lag in range(1, 11)]
for lag in range(1, 11):
idf[f"l3Fvel_lag{lag}"] = idf.sort_values("raceDate").groupby("horseId")[
"last3F_vel"].shift(lag)
lagcolumns3 = [f"l3Fvel_lag{lag}" for lag in range(1, 11)]
for lag in range(1, 11):
idf[f"toL3Fvel_lag{lag}"] = idf.sort_values("raceDate").groupby("horseId")[
"toL3F_vel"].shift(lag)
lagcolumns4 = [f"toL3Fvel_lag{lag}" for lag in range(1, 11)]
過去成績から出走レースごとの脚質分布の計算
dflist = {}
lagcolumns = [f"clsName_lag{lag}" for lag in range(1, 11)]
for g, dfg in tqdm.tqdm(idf[["raceId",] + lagcolumns].groupby("raceId")):
dflist[g] = (pd.Series(dfg[lagcolumns].values.reshape(-1)
).value_counts() / dfg[lagcolumns].notna().sum().sum()).to_dict()
dfcls = pd.DataFrame.from_dict(dflist, orient="index")
idfp = pd.merge(idf, dfcls.reset_index(names="raceId"), on="raceId")
idfp3 = idfp.set_index(["field", "distance"])
idfp3["prePace3F_diff"] = idfp[["field", "distance", "prePace3F"]
].groupby(["field", "distance"])["prePace3F"].mean()
idfp["prePace3F_diff"] = idfp["prePace3F"] - \
idfp3["prePace3F_diff"].reset_index(drop=True)
以上でデータ準備完了
9-3.持ちタイム×前走の脚質を使って上り3Fタイム情報の推定¶
上り3Fは全力疾走する距離なため、その日の競走馬の体調に左右されやすく計測タイムも小数点1位までしかなくかなり推定が困難だと思われる。
そのため、タイムの推定ではなく順位の推定を行うこととする
9-4.LightGBMのモデル作成案
- モデル:ランク学習モデル
- 目的変数:
上り3Fタイムのランク推定 - 説明変数: 前走情報の脚質割合とmochiTimeの平均値、そのほかレース情報のカテゴリ
- 学習期間: 2014年~2019年
- 検証期間: 2020年
- テスト期間: 2021年
9-5.特徴量作成¶
feature_columns = clsnames + \
[
"field", "place", "dist_cat", "distance",
"condition", "raceGrade", "horseNum", "direction",
"inoutside", 'mochiTime_mean', 'mochiTime3F_mean',
'weather', 'mochiTime_mean_div', 'mochiTime3F_mean_div',
"mochiTime_diff", "mochiTime", "mochiTime3F", "mochiTimeDiff",
"mochiTime_div", "mochiTime3F_div", "horseId", "breedId",
"bStallionId", "b2StallionId", "stallionId",
"mochiTime_rank", "mochiTime3F_rank", "mochiTimeDiff_rank",
"mochiTime_dev", "mochiTime3F_dev", "mochiTimeDiff_dev"
]+lagcolumns+lagcolumns2+lagcolumns3+lagcolumns4
label_column = "last3F_rank" # 上り3Fの順位
cat_list = [
"field", "place", "dist_cat", 'weather',
"condition", "direction", "inoutside", "horseId",
"breedId", "bStallionId", "b2StallionId", "stallionId"
]+lagcolumns
for cat in cat_list:
idfp[cat] = idfp[cat].astype("category")
for mochi in ["mochiTime", "mochiTime3F", "mochiTimeDiff"]:
idfp[f"{mochi}_rank"] = idfp.sort_values(
"odds").groupby("raceId")[mochi].rank()
for mochi in ["mochiTime", "mochiTime3F", "mochiTimeDiff"]:
idfp[f"{mochi}_dev"] = (idfp[mochi] - idfp[["raceId", mochi]].groupby(
"raceId")[mochi].mean())/idfp[["raceId", mochi]].groupby("raceId")[mochi].std()
idfp["mochiTime3F_mean_div"] = 200*60/idfp["mochiTime3F_mean"]
idfp["mochiTime_mean_div"] = 200*60/idfp["mochiTime_mean"]
idfp["mochiTime_div"] = 200*60/idfp["mochiTime"]
idfp["mochiTime3F_div"] = 200*60/idfp["mochiTime3F"]
# toL3F_velが走破速度(分速)になっているので、200m単位のタイムに変換
idfp["L3F_diff"] = idfp["last3F_vel"] - idfp["toL3F_vel"]
idfp["last3F_rank"] = idfp.sort_values("time").groupby("raceId")[
"last3F"].rank(method="first")
dffl = idfp[["raceId", "raceDate"]+feature_columns +
["prePace3F", "toL3F_vel_mean", "L3F_diff", "last3F_vel", "last3F", "last3F_rank"]]
dffl
9-6.モデルの学習¶
dftrain, dfvalid, dftest = dffl[dffl["raceId"].str[:4] <= "2019"], dffl[dffl["raceId"].str[:4].isin(
["2020"])], dffl[dffl["raceId"].str[:4].isin(["2021"])]
params = {
'metric': 'rmse',
"categorical_feature": cat_list,
'boosting_type': 'gbdt',
'seed': 777,
}
# train_data = lgbm.Dataset(
# dftrain[feature_columns], label=dftrain[label_column])
# valid_data = lgbm.Dataset(
# dfvalid[feature_columns], label=dfvalid[label_column])
# test_data = lgbm.Dataset(dftest[feature_columns], label=dftest[label_column])
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
"categorical_feature": cat_list,
'ndcg_eval_at': [1,],
'boosting_type': 'gbdt',
"label_gain": ",".join([str(n**3) for n in range(1, 19)]),
'seed': 777,
}
train_data = lgbm.Dataset(
dftrain[feature_columns], label=dftrain["horseNum"]-dftrain[label_column],
group=dftrain.groupby("raceId")["raceId"].count().values)
valid_data = lgbm.Dataset(
dfvalid[feature_columns], label=dfvalid["horseNum"]-dfvalid[label_column],
group=dfvalid.groupby("raceId")["raceId"].count().values)
test_data = lgbm.Dataset(dftest[feature_columns], label=dftest["horseNum"]-dftest[label_column],
group=dftest.groupby("raceId")["raceId"].count().values)
# モデル学習
model = lgbm.train(params, train_data, num_boost_round=1000, valid_sets=[
train_data, valid_data], callbacks=[
lgbm.early_stopping(
stopping_rounds=50, verbose=True,),
lgbm.log_evaluation(50 if True else 0)
],)
9-7.推論結果の追加¶
dftrain["pred"] = model.predict(
dftrain[feature_columns], num_iteration=model.best_iteration)
dfvalid["pred"] = model.predict(
dfvalid[feature_columns], num_iteration=model.best_iteration)
dftest["pred"] = model.predict(
dftest[feature_columns], num_iteration=model.best_iteration)
9-8.特徴量重要度の確認¶
dfimp = pd.DataFrame(model.feature_importance(
"gain"), index=feature_columns, columns=["重要度"]).round(3).sort_values("重要度")
dfimp[dfimp["重要度"] > 0]
結果からレースごとの出走馬の持ちタイムの平均情報が最も重要であり、次にレース距離, 競馬場, 馬場, 母の血統, レースグレードと続いている。
dft = pd.merge(
idfp,
dftest[["raceId", "horseId", "pred"]],
on=["raceId", "horseId"]
)
dfv = pd.merge(
idfp,
dfvalid[["raceId", "horseId", "pred"]],
on=["raceId", "horseId"]
)
ランダムにレース情報を確認してみる。
実際に予測結果のペース情報が出走馬の出走タイムに沿っているか確認する。
今回の予測値のランク(pred_rank)と正解のランク(ans_rank)を見比べる
raceId = np.random.choice(dft[dft["raceGrade"].isin(
[8])]["raceId"].unique())
raceId = "202105010811"
for dfvt in [dft, dfv]:
dfvt["pred_rank"] = dfvt.sort_values("time").groupby("raceId")[
"pred"].rank(method="first", ascending=False)
dfvt["ans_rank"] = dfvt.sort_values("time").groupby(
"raceId")[label_column].rank(method="first", ascending=True)
dft[
dft["raceId"].isin([raceId])
][[
"pred_rank", "ans_rank", "pred", "label", "raceId", "raceName", "horseId",
"favorite", "last3F", "dist_cat", "distance", "field", "place"
]].sort_values("pred_rank", ascending=True)
実際にpred_rankが1.0のもの(horseId=2013105399)に対して、正解ランクが1.0と予測されているのが分かるが、その次に6位や8位のものが来ていたりとかなりムラがある。
正直最後の全力疾走のタイム順位の予測なので、さすがにこの手の精度が落ちるのは致し方ない。
良く予測できている方だと考える
実際の正解ランクと今回の予測結果のランク分けに関連があるか確認する
dft[["ans_rank", "pred_rank"]].corr()
かなり関係がありそうである
9-9.色々と分布の確認¶
# region plot
ans_col = "ans_rank"
dft["pred_q90"] = dft["raceId"].map(dft[["raceId", "pred_rank"]].groupby(
"raceId")["pred_rank"].quantile(0.9).to_dict())
dft["pred_q90"] = dft["pred_rank"] >= dft["pred_q90"]
dft[dft["pred_q90"]][ans_col].value_counts().sort_index()
dft["pred_q10"] = dft["raceId"].map(dft[["raceId", "pred_rank"]].groupby(
"raceId")["pred_rank"].quantile(0.1).to_dict())
dft["pred_q10"] = dft["pred_rank"] <= dft["pred_q10"]
dft[dft["pred_q10"]][ans_col].value_counts().sort_index()
idft = pd.concat(
[
dft[dft["pred_q10"]][ans_col].value_counts(normalize=True).sort_index(
).to_frame().rename(columns={"proportion": "上位10%"}),
dft[dft["pred_q90"]][ans_col].value_counts(normalize=True).sort_index(
).to_frame().rename(columns={"proportion": "下位10%"})
],
axis=1
)
idft.sort_index(ascending=False).cumsum().sort_index(ascending=True).rename(
columns={"上位10%": "上位10%_累積", "下位10%": "下位10%_累積"}, index=lambda x: x-1).plot(ax=idft.plot.bar(alpha=0.5).twinx())
plt.title("pred_rankと上り3F順位の関係")
plt.legend(loc="upper right", bbox_to_anchor=(
1., 0.85),)
plt.show()
# endregion
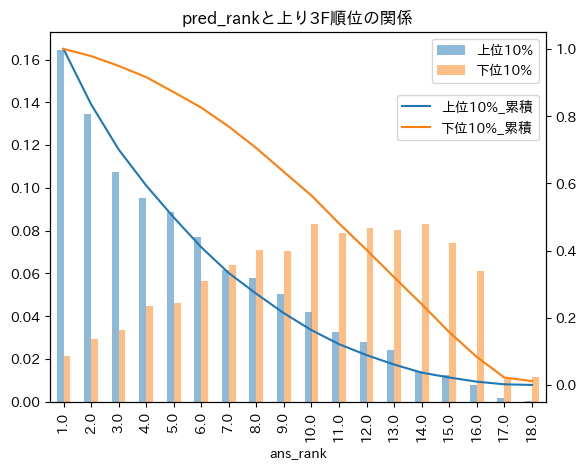
予測ランクと正解ランクの分布の関係を確認
idftlist = []
for g, idfgtg in dfv.groupby("pred_rank"):
idftlist += [idfgtg["ans_rank"].value_counts(
normalize=True).to_frame(name=g).T]
idft: pd.DataFrame = pd.concat(idftlist)[list(range(1, 19))]
idft
テストデータに対して予測値のランクが1位のものを選択した場合の正解ランク(ans_rank)の累積分布を出してみる
一応レースグレード別に出してみる
pd.concat([dft[dft["pred_rank"].isin([1]) & dft["raceGrade"].isin([i])]["ans_rank"].value_counts(
normalize=True).sort_index().cumsum().to_frame(name=f"Grade: {i}").T for i in range(9)])
全体的にみて、予測タイムが最も早いデータ(pred_rank=1)を選択するとそのうちの2割前後で上り最速を選択出来ている。
累積分布で考えてみると予測タイム最速のものを選択した場合、上位8位までに入る割合が全体の80%で、上位4位に入るのは全体の50%である。
もう少し精度を上げて全体の80%が上位3位に入るように改良をしたいが、さすがにまだ難しいかもしれない。

コメント