
少ないアクセス数で1年間の競馬データを取得する方法
※最近某サイト様でのスクレイピング対策が実施されました。本記事で紹介する内容はスクレイピングを容認・推奨するものではなく、個人の責任で実施して頂くようよろしくお願いいたします。
また、有料公開している私のスクレイピングソースでは、その辺の対応も考慮したスクレイピング先への負荷を極力減らしたソースを提供しています。ご参考にされたい方は、ぜひ最後のリンクよりソースを入手いただければと思います。
それでは本丸に入ります。このサイトを訪れていただいた方々は、よくあるPythonで競馬データをスクレイピングしてみた系のサイト(参考1, 参考2)を参考にしてスクレイピングしている方が多いと思いますが、このやり方だとサイト側に不要な負荷を与える可能性が高いので控えた方が良いということを伝えたいです。
参考に挙げているやり方の勘所をざっくりまとめると、netkeiba様のレース情報のサイトURLである「https://db.netkeiba.com/race/{raceId}」の{raceId}部分を以下のような多重のfor文で総当たりしている形にしていると思います。というかほとんどの方がそれでスクレイピングしていると思います。
year="2023"
for place in range(1, 11, 1):
for kaisu in range(1, 6, 1):
for hiniti in range(1, 9, 1):
for raceNum in range(1, 13, 1):
raceId = year
+ str(place).zfill(2)
+ str(kaisu).zfill(2)
+ str(hiniti).zfill(2)
+ str(raceNum).zfill(2)
(...サイトアクセス処理...)
time.sleep(1)自分も当初は上記のやり方でしていたのですが、この総当たりのやり方だと合計4,800回もサイトにアクセスすることになります。
1年間の中央競馬の開催数をご存知でしょうか?おおよそ3,500回しか開催されていません。
つまり、いままで皆がしてきたスクレイピング方法は1年分のデータを取得するのに1,300回あまりも無駄にnetkeiba様にアクセスしていたことになります。
スクレイピングする際には、マナーとして1アクセス後再アクセスに1~2秒空けないといけません。そのため、時間にして1,300秒~2,600秒(20分~40分)も無駄に時間を使っていることになります。
10年~15年分のデータが欲しい場合、時間が無駄になりすぎることは火を見るよりも明らかだと思います。
ということで、本記事ではそのような無駄アクセスを減らす方法を共有します。
スクレイピングする時間を減らすということはそれだけnetkeiba様へのアクセス機会を減らすことにつながります。一度きりだし楽だからと多重for文を乱用するのはやめるように努めましょう。
本記事で話すこと
- 前提条件
- Pythonの環境構築
- 少ないアクセス数でスクレイピングする方法の具体的なステップ
- (有料)実際のソース
前提条件:動作環境
- Windows 10 pro
- メモリ32GB
- Python 3.10.5
- エディタ:VScode
Pythonは事前にインストールしておいてください。
Python環境構築
コマンドラインツールを開いて、適当な作業するためのフォルダ配下まで移動。画像の場合だと「E:¥sample_dir>」のこと。
エクスプローラを開いてsample_dirというフォルダがいるところまでcdコマンドで移動してください。(sample_dirは好きなフォルダ名にしてください。特に意味はないので。以降はsample_dirとして話を進めて行きます。)
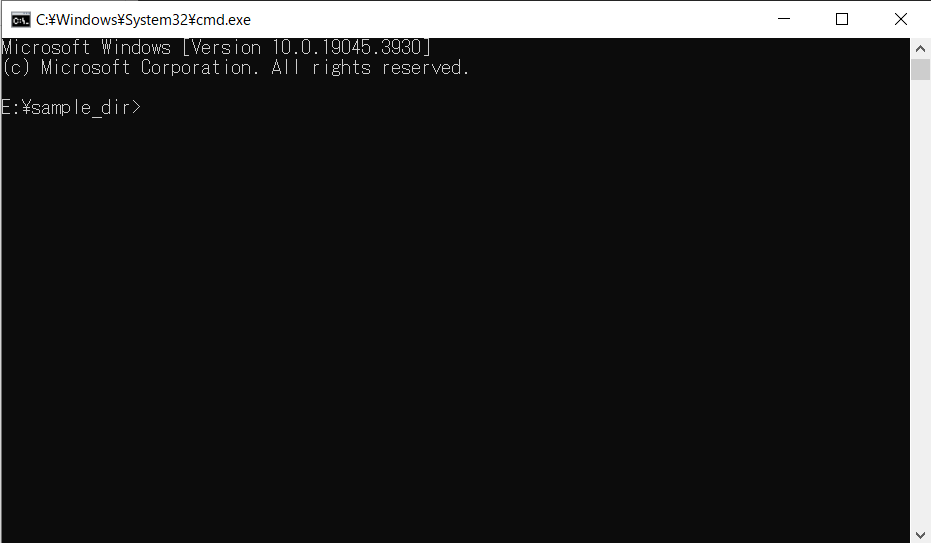
既存のPython環境とのバッティングを回避するために、sample_dir配下にPythonの仮想環境を作成しましょう。以下の画像のようにコマンドを実行してください。
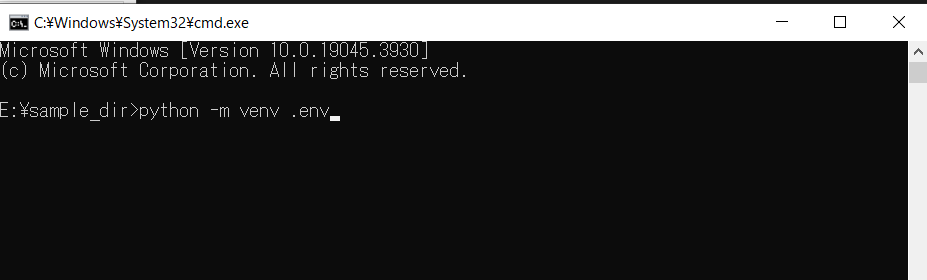
エクスプローラを見てみると「.env」フォルダが作成されている。このフォルダに「.env\Scripts\Python.exe」というPython実行ファイルが作成されている。(Mac, Linux民は「.env/bin/python.exe」にある。)
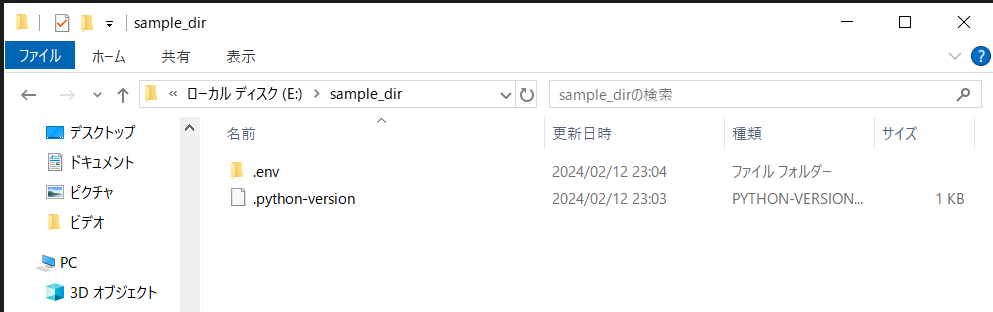
最後に以下の画像のコマンドを実行して仮想環境に入ってください。先頭が「(.env)E:\sample_dir」となっていたらOKです。

Windowsの場合
.env\Scripts\activateMac/Linuxの場合
source .env/bin/activate必要なPythonパッケージ一覧
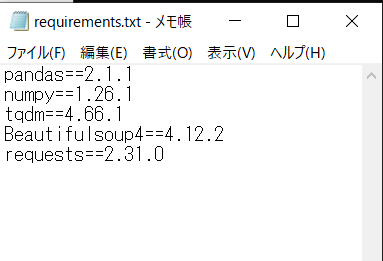
- pandas==2.1.1
- numpy==1.26.1
- tqdm==4.66.1
- Beautifulsoup4==4.12.2
- requests==2.31.0
上記パッケージ一覧をrequirements.txtという名のテキストファイルにすべて記載してください。以下にイメージ画像置きます。
そのrequirements.txtファイルを、sample_dir配下に設置して、pipでまとめてインストールしましょう。以下のコマンドを実行してください。
pip install -r requirements.txtインストールが完了したら、Python環境構築完了です。お疲れさまでした。
少ないアクセス数で競馬データをスクレイピング
必要なのは以下の4ステップ
- カレンダー情報のHTMLソースを取得(1年分なので12回アクセス)
- カレンダー情報のHTMLソースから開催日のID取得(おおよそ100件分の開催日情報が手に入る)
- 開催日IDから各競馬場の開催レース一覧にアクセスしレースIDを取得(Step2で得た100件分のアクセス)
- 取得したレースIDを使ってレース情報のHTMLソースを取得(レース開催日分の約3,500回アクセス)
以上になります。このやり方でスクレイピングすれば、約3,600回分のアクセス回数で1年分のレース情報を過不足なく取得することが可能です。
よくあるやり方と比較すると、1,200回分も少ないアクセス数で取得することができます。
具体的なアクセス順序
以下にプログラムを書く際に参考となるアクセス順序を示します。
1.カレンダー情報のHTMLソースを取得する
カレンダー情報にその月のレース開催日の情報が埋め込まれています。具体的には以下のサイトURLにアクセスしてみてください。
カレンダー情報URL:https://race.netkeiba.com/top/calendar.html?year=2024&month=1
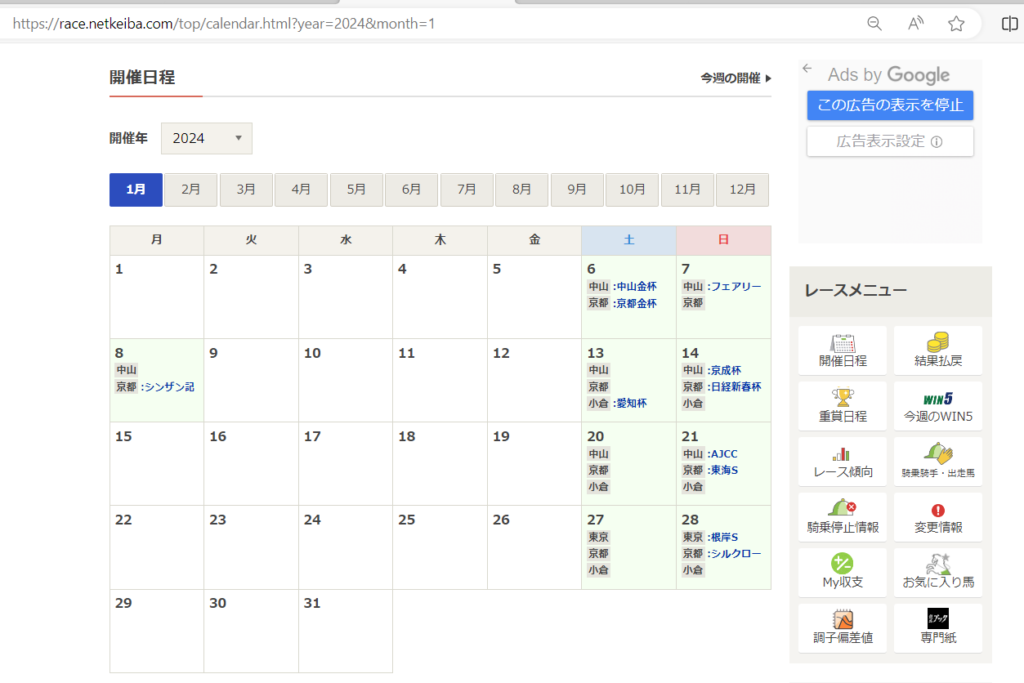
上記サイトのキャプチャ画像にある1月6日や13日をクリックするとその日のレース一覧のサイトが開くと思います。つまり、HTMLソースを解析して開催日を取得することが可能だということです。
以下のサンプルコードをもとにカレンダー情報のHTMLソースを取得するようにしましょう。
import requests, time
# 2023年のレース情報を取得したい
CALENDAR_URL = "https://race.netkeiba.com/top/calendar.html?year={year}&month={month}"
calendar_url_list = [CALENDAR_URL.format(year=2023, month=month) for month in range(1, 13)]
# HTMLソースを取得する
calendar_html_list = []
for calendar_url in calendar_url_list:
r = requests.get(calendar_url) # ここでサイトアクセス
time.sleep(1) # なので1秒休み
calendar_html_list += [r.content] # htmlソースをリストに保存
2.カレンダー情報のHTMLソースから開催日のIDを取得する
題記の通り、カレンダー情報のHTMLソースから開催日のIDを取得しましょう。以下がサンプルコードです。
import re, gc
from bs4 import Beautifulsoup
date_id_list = [] # 開催日IDが入ります。ex: 20230105, 20230107など
for calendar_html in calendar_html_list:
soup = Beautifulsoup(calendar_html, "html.parser")
table_data = soup.find("table", class_="Calendar_Table")
link_set = table_data.findAll("a")
date_id_list += [
re.search(r"\d+$", link.get("href")).group()
for link in link_set
]
del calendar_html_list # HTMLソースはメモリ食うのでこまめに削除しておきましょう。
# ちょっと詳しいこと分かりませんが、delした後に以下のコマンドも
# 実行しておくと動作が重くならないっぽい(調べてください。)
gc.collect()取得した開催日IDは次のアクセス先である以下のURLの{racedate}部分に埋め込んで使用します。
https://db.netkeiba.com/race/list/{racedate}/開催日IDから各競馬場の開催レース一覧にアクセスしレースIDを取得
開催日IDが取得できたので、以下のサンプルコードから開催レース一覧のサイトにアクセスしてHTMLソースからレースIDを取得するようにしましょう。
import requests
import time
from bs4 import Beautifulsoup
import re
# 接続先URLの作成
RACEDATE_URL = "https://db.netkeiba.com/race/list/{racedate}/"
racedate_url_list = [RACEDATE_URL.format(racedate=racedate) for racedate in racedate_id_list]
# レース一覧URLのHTMLソードを取得する
racedate_html_list = []
for racedate_url in racedate_url_list:
r = requests.get(racedate_url)
time.sleep(1)
racedate_html_list += [r.content]
# HTMLソースからレースIDを取得する
raceId_list = []
for racedate_html in racedate_html_list:
soup = Beautifulsoup(racedate_html, "html.parser")
table_data = soup.body.findAll('dl', class_='race_top_data_info fc')
raceId_list += [
re.search(
r'^/race/\d+',
link.find('a').get('href')
).group().split('/')[-1]
for link in table_data
if link.find('a').get('title')
]
# お約束の不要なHTMLソースは削除
del racedate_html_list
gc.collect()4.取得したレースIDを使ってレース情報のHTMLソースを取得
最後に取得したレースID一覧を以って、レース情報のスクレイピングを実行。好きな形式に変換して保存してください。サンプルコードではpickleファイルで保存しています。
import requests, time, pathlib
import pickle
output_dir = pathlib.Path("./output")
output_dir.mkdir(exist_ok=True)
RACE_URL = 'https://db.netkeiba.com/race/{raceId}'
for raceId in raceId_list:
race_url = RACE_URL.format(raceId=raceId)
r = requests.get(race_url)
time.sleep(1)
with open(f"{raceId}.pkl", "+wb") as f:
pickle.dump(r.content, f)
ゼロから作る競馬予想モデル・機械学習入門を公開しています
すみません、netkeiba様への負荷を減らすためにも容易にコピペしてスクレイピングできてしまうような形で公開するのも良くないと思い、実際に自分がしているスクレイピングのソースは有料公開にします。
スクレイピングソースの他、競馬予想AIの開発に必要なデータ前処理の仕方からはじまり、競馬予想AIを分析するWEBアプリの作成、LightGBMを使った1着馬の分類モデル、オッズを使った回収率重視のLightGBMモデル、最近では深層学習を使った競馬予想AIの開発方法も解説したJupyter Notebookを公開しています。
ぜひ、今回を機にPythonで作る競馬予想AI開発にチャレンジしてみませんか?
公開場所はBookersになります。以下リンク先です。
実際の動かし方は、Bookersを参照してください。

Bookersには便利機能があり、Bookersアカウントを作成してYouTube連携後、以下の私のチャンネルを登録して頂けると、1,000円引きでスクレイピングのソースを購入できるようになります!


コメント
すいません、以前同じようなコメント/質問しました。
python src\scraping\main.py –start-year 2010 –end-year 2025 –all –scraping-horse-birth
のコマンドを走らせると、途中で
A value is trying to be set on a copy of a slice from a DataFrame.
というエラーメッセージが表示されます。出るタイミングは下記参照。
環境は、Windows11/VScodeです。ご報告まで。自分でも調べてみますが、簡単にfixできるようなら教えてください。
Extract HorseId from htmlsrc in 2025.: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1799/1799 [02:02<00:00, 14.74it/s]
C:\Users\katsu\Dropbox\NewDropBox\Keiba\dev-um-ai-20250420\dev-um-ai-5-model-operation-took\.\src\scraping\data_scraper.py:151: SettingWithCopyWarning: /1799 [02:01<00:00, 16.92it/s]
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dfhorseId["year"] = dfhorseId[self.html_db.HORSEURL.horseId].apply(
scraping horse source in 2007: 71%|████████████████████████████████████████████████████████████████████████▉ | 3052/4311 [2:51:41<1:22:44, 3.94s/horse]
コメントありがとうございます。
そちらのメッセージですが、エラーではなく警告メッセージになります。
結論から申し上げますと問題ないです
DataFrameのコピーに代入してる可能性があるけど大丈夫そう?って意味合いのもので、pandasのDataFrame使ってると良く出てくる警告です
現状のソースであれば大丈夫なので、特段気にする必要はありません
もし気になる場合は「data_scraper.py」ファイルの「import pandas as pd」してるすぐ下に以下のコードを入れると出なくなります
import pandas as pd
pd.options.mode.chained_assignment = None # ← これを入れる