
はじめに
私は競馬予想AIの開発をしています。動画で制作過程の解説をしています。良ければ見ていってください。

また、共有するソースの一部は有料のものを使ってます。
同じように分析したい方は、以下の記事から入手ください。

2.重賞レースと血統の関係
G1などの重賞レースで好成績を残している競走馬は、種牡馬や繫殖牝馬として次の世代の競走馬を輩出している。
その親の血統によっては、より勝ちやすい血統が存在しているのかどうか確認してみたい。
確認の方針としては、過去数年~十数年の範囲で産駒が重賞レースを制覇した競走馬の中で、
種牡馬や母父の血統によって重賞クラスに勝利するまでの期間に違いがあるかを確認してみる
2-0-1.必要そうなものをインポート
import random
from wordcloud import WordCloud
import seaborn as sns
import japanize_matplotlib
import matplotlib.pyplot as plt
import re
from typing import Literal
import pathlib
import warnings
import sys
import pandas as pd
sys.path.append("..")
from src.core.db.controller import execSQL, getTableList, getDataFrame # noqa
from src.data_manager.preprocess_tools import DataPreProcessor # noqa
from src.data_manager.data_loader import DataLoader # noqa
warnings.filterwarnings("ignore")
2-0-2.血統データをDBから取得
2-0-2-1.接続先DB情報
# 接続先DB (このnotebookの場所が「notebook」フォルダにあるので一つ上の階層に戻ってDBファイルパスを生成)
root = pathlib.Path(".").absolute().parent
dbpath = root / "data" / "keibadata.db"
dbpath
2-0-2-2.DBから血統情報のテーブル一覧を取得
# 血統情報が入っているテーブルは「horseblood」という接頭辞がついたテーブルなので、その一覧を取得
horseblood_list = [tbl for tbl in getTableList(dbpath) if "horseblood" in tbl]
horseblood_list.sort(key=lambda x: int(x[-4:]))
horseblood_list
2-0-2-3.テーブル一覧から5代血統情報をDataFrameに変換
# DBから取得:concatでhorseblood_listにあるテーブル情報のDataFrameをすべて結合する
dfblood = pd.concat(
[getDataFrame(tbl, dbpath) for tbl in horseblood_list], ignore_index=True)
dfblood
2-0-3.2000年から2023年の出走情報を取得
2-0-3-1.ベース前処理の実行
start_year = 2000
end_year = 2023
data_loader = DataLoader(start_year, end_year, dbpath=dbpath)
dataPreP = DataPreProcessor()
df = data_loader.load_racedata()
df = dataPreP.exec_pipeline(df)
以上で準備完了
2-0-4.パート1の内容: レースのクラスのグレード分けを行う
前回の内容から以下のマッピングをそのまま流用して、グレード分けを行う
前回記事

# それぞれのマッピングを作っておく
def map_race_grade(data: str):
if re.search(r"\(G1\)", data) or re.search(r"\(GI\)", data):
return 7
if re.search(r"\(G2\)", data) or re.search(r"\(GII\)", data):
return 6
if re.search(r"\(G3\)", data) or re.search(r"\(GIII\)", data):
return 5
return None
grade_mapping_dict = {
'4歳未勝利': 0, '4歳新馬': 0, '4歳以上500万下': 1, '4歳500万下': 1, '4歳以上900万下': 2, '4歳以上オープン': 4,
'4歳以上1600万下': 3, '4歳オープン': 4, '4歳未出走': 0, '5歳以上オープン': 4, '4歳900万下': 2, '3歳新馬': 0,
'3歳未勝利': 0, '3歳オープン': 4, '3歳500万下': 1, '3歳未出走': 0, '3歳以上オープン': 4, '3歳900万下': 2,
'2歳新馬': 0, '3歳以上500万下': 1, '3歳以上1000万下': 2, '2歳未勝利': 0, '2歳オープン': 4, '3歳以上1600万下': 3,
'2歳500万下': 1, '4歳以上1000万下': 2, '3歳1000万下': 2, '3歳以上1勝クラス': 1, '3歳以上2勝クラス': 2,
'3歳以上3勝クラス': 3, '2歳1勝クラス': 1, '3歳1勝クラス': 1, '4歳以上1勝クラス': 1, '4歳以上2勝クラス': 2,
'4歳以上3勝クラス': 3
}
# クラスをグレードに置き換える
idf = df[df["raceName"].map(map_race_grade).notna()
]["raceName"].map(map_race_grade)
df["raceGrade"] = pd.concat(
[idf, df[~df.index.isin(idf.index)]["raceDetail"].map(grade_mapping_dict)])
2-0-5.パート1の内容: 種牡馬と繁殖牝馬の種牡馬情報を追加する
前回の内容から出走情報に父と母父、そして追加で、母母父と父父そして父父父の情報も追加する
def add_blood_info_to_df(df: pd.DataFrame, mode: Literal["s", "ss", "sb", "b", "bs", "bb", "sss", "ssb", "sbs", "sbb", "bss", "bsb", "bbs", "bbb"]):
index_map = {
"s": (0, "stallion", "gen1"), "ss": (0, "sStallion", "gen2"), "sb": (8, "sBreed", "gen2"),
"sss": (0, "s2Stallion", "gen3"), "ssb": (4, "s2Breed", "gen3"), "sbs": (8, "sbStallion", "gen3"), "sbb": (12, "sbBreed", "gen3"),
"b": (16, "breed", "gen1"), "bs": (16, "bStallion", "gen2"), "bb": (24, "bBreed", "gen2"),
"bss": (16, "bsStallion", "gen3"), "bsb": (20, "bsBreed", "gen3"), "bbs": (24, "b2Stallion", "gen3"), "bbb": (28, "b2Breed", "gen3"),
}
idx, prefix, genCol = index_map[mode]
idf = dfblood.iloc[idx::32].reset_index(drop=True)
idf[genCol] = idf[genCol].str.split("\n", expand=True)[
0].str.replace("\n", "")
df[f"{prefix}Id"] = df["horseId"].map(
idf.set_index("horseId")[f"{genCol}ID"])
df[f"{prefix}Name"] = df["horseId"].map(idf.set_index("horseId")[genCol])
return df, idf[["horseId", genCol, f"{genCol}ID"]].rename(columns={genCol: "GenName", f"{genCol}ID": "GenID"})
df, dfstallion = add_blood_info_to_df(df, "s")
df, dfsStallion = add_blood_info_to_df(df, "ss")
df, dfbStallion = add_blood_info_to_df(df, "bs")
df, dfs2Stallion = add_blood_info_to_df(df, "sss")
df, dfb2Stallion = add_blood_info_to_df(df, "bbs")
df[["horseId", "stallionId", "stallionName", "sStallionId", "sStallionName",
"s2StallionId", "s2StallionName", "bStallionId", "bStallionName"]]
以上で前回分で分析した情報の追加完了
2-1.そもそも重賞レースってどのくらい凄いの?
レースのグレードごとに出走する競走馬の数をカウントすれば、どれだけ重賞レースに出走できる競走馬数が少ないのかが分かる
出し方は、raceGradeカラムでgroupbyしてhorseIdカラムに対してユニーク数を出す
df.groupby("raceGrade")["horseId"].nunique().rename(
index=lambda x: f"Grade {x}")
おかしい、ピラミッド形式になっているはず・・・
もう少し詳しく年度別に見てみる
idf = df.copy()
idf["year"] = df["raceDate"].dt.year
idfg = pd.concat(
[
idfg.groupby("year")[["horseId"]].nunique().rename(
columns={"horseId": f"Grade {col}"}) for col, idfg in idf.groupby("raceGrade")
] + [idf.groupby("year")[["horseId"]].nunique().rename(
columns={"horseId": f"Grade ALL"})], axis=1
)
idfg["G race"] = idfg[["Grade 5", "Grade 6", "Grade 7"]].sum(axis=1)
idfg["G race rate"] = (100*idfg["G race"]/idfg["Grade ALL"]).round(1)
display(idfg)
こうやって見ると、年間の出走馬数が8000~11500頭いる中、
G1~G3を出走する競走馬は毎年1100~1350頭であり、
全体の大体12%の競走馬が重賞レースを走っている
厳密には1年間に同じ競走馬が何度も出走するほか、1着になるとクラスが上がるため
同じ馬を別のクラスで重複しているが、クラスごとの出走馬数を数えていることに注意
とはいえ、数字だけだとレースグレード同士の大小関係が見づらいのでヒートマップにする
比較しやすいようにグレードのカラムごとの差分を見ると分かりやすい
そのため、(Grade x) - (Grade x+1)を計算し、(Grade x) < (Grade x+1)の場合はFalse, (Grade x) >= (Grade x+1)の場合はTrueとする
つまり、グレードが上がっていくたびに出走馬の数が減っていくはずなので、
ヒートマップはすべて真っ白になるはず
sns.heatmap(~(idfg[idfg.columns[:8]].diff(axis=1) > 0),
annot=True, linewidths=0.01)
plt.show()
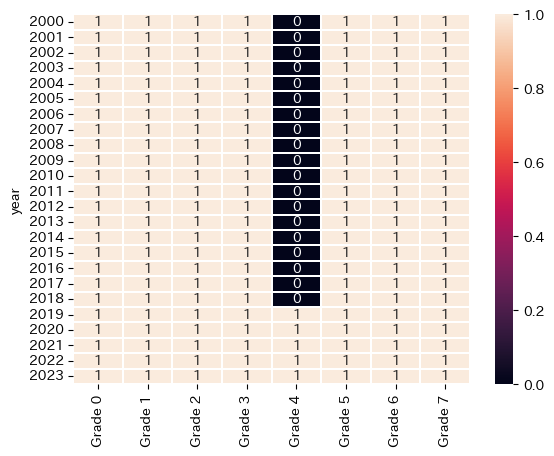
結果をみると、2000年から2018年ではオープンクラスであるGrade 4が
3勝クラスであるGrade 3よりも出走馬の数が多くなっているのに、
なぜか2019年以降からはピラミッド形式になっている…
どうやら調べると2019年より競馬の出走条件に大きな変更があったようで、
具体的には、2019年から4歳馬の降級制度を廃止したようである。(ソース:https://dir.netkeiba.com/keibamatome/stayhome/2020s_rule_detail.html)
つまり、下級のレースで誤って1位になってしまい、
分不相応な階級(つまりグレード)のレースに出走しなければならない場合でも、
4歳になったとて下のグレードのレースに出走することができなくなったとのこと
2018年までは4歳馬になった段階でこれまで獲得してきた賞金が半分になったそう。
そのおかげで下級のレースへ出走できた。つまり、4歳馬以降は古馬と呼ばれており、
2,3歳馬との実力差を埋めるためと競走馬不足を補うための制度だったとのこと
だが、競走馬の生産が盛んになり、競走馬薄の現状もなくなりその必要がなくなったとのこと
そうなってくると、オープンクラスの方が3勝クラスよりも出走する
競走馬が多いというのはいささか違和感のある結果である。
2-2.上記とはまた別に見落としがあった
レースグレードの分け方に問題があったようだ
以下の分け方の方が正しいとのこと
2-2-1.クラス分けグレード表・改
| 獲得賞金 | クラス | グレード |
|---|---|---|
| 0 | 新馬, 未勝利 | 0 |
| 500万下 | 1勝クラス | 1 |
| 1000万下, 900万下 | 2勝クラス | 2 |
| 1600万下 | 3勝クラス | 3 |
| それ以上 | オープン | 4 |
| — | リステッド | 5 |
| — | G3 | 6 |
| — | G2 | 7 |
| — | G1 | 8 |
というわけで、リステッドレースが何なのか調べる
2-2-2.リステッドクラスの調査
そもそもどこにいるのやら
旧クラス分けグレード表でいうと4以上の中にいるはず
df[df["raceGrade"].isin([4, 5, 6, 7])]["raceDetail"].unique()
ない。
raceDetailカラムにないのかもしれない
旧クラス分けグレード表でいう4の中だけで「raceName」カラムをみてみる
df[df["raceGrade"].isin([4,])]["raceName"].unique()
あまりにも多い。ここからリステッドであるものとそうでないものを導くのは無理がある。
しかしよく見ると「(L)」やら「(OP)」やらがついてるものがいる
直感的に「(L)」がリステッドクラスなのだろう
もしかすると「リステッド」とか含んでいるraceNameがあるかもしれない
こういう時は文字列系のメソッドであるcontainsを使う
df[df["raceName"].str.contains(
r"\(L\)|リステッド", regex=True)]["raceName"].unique()
リステッドと含まれているレース名はなかったが、ひとまず「(L)」を含むレース名は取得できた
一部を確認してみる。
大阪城ステークス(L)で確認
2023年レース結果URL:https://race.netkeiba.com/race/result.html?race_id=202309010811
リステッドクラスとか書いてくれてないので、ちょっと良く分からない・・・
とりあえず、過去24年間の出走データからリステッドクラスのユニーク数を出してみると65レースあった
df[df["raceName"].str.contains(r"\(L\)", regex=True)]["raceName"].nunique()
JRAの公式サイトで調べると普通に一覧で出してくれていた。
https://www.jra.go.jp/keiba/program/2019/pdf/listed.pdf
https://www.jra.go.jp/keiba/program/2020/pdf/listed.pdf
https://www.jra.go.jp/keiba/program/2021/pdf/listed.pdf
https://www.jra.go.jp/keiba/program/2022/pdf/listed.pdf
https://www.jra.go.jp/keiba/program/2023/pdf/listed.pdf
https://www.jra.go.jp/keiba/program/2024/pdf/listed.pdf
# 一応年度別にリステッドクラスのレース数を見る
idf = df.copy()
idf["year"] = df["raceDate"].dt.year
idf[df["raceName"].str.contains(r"\(L\)", regex=True)].groupby('year')[
"raceName"].nunique()
厄介なことに年度ごとに開催するレース数が違うが、だいたい年間で63レースほどある。
先の集計結果ではユニーク数は65レースあったが、2019年から2023年までの間に
リステッドクラスとして追加されたものやなくなったものがあるのかもしれない
公式サイトの方で2019年で1レース足らないが、おそらく前処理の段階で除外されてしまったのかもしれない
調べるのは面倒で1レースだけであるから、大きな影響はないとして見逃す
とりあえず、2019年以降からリステッドクラスとなったレースは2018年以前でもリステッドクラスとみなすことにする
# (L)が入っているレース名だけ取り出して、(L)を取り除いたレース名で検索できるか確認する
for rname in df[df["raceName"].str.contains(r"\(L\)", regex=True)]["raceName"].unique():
print(df[df["raceName"].str.contains(
rname.replace("(L)", ""))]["raceName"].unique())
上手く行ってそうだ
2-3.レースのクラスのグレード分けを改めて行う
ということで、リステッドクラス用のマッピングを作成してグレード分けする
listed_racename_list = [rname.replace("(L)", "") for rname in df[df["raceName"].str.contains(
r"\(L\)", regex=True)]["raceName"].unique()]
listed_racename_list = idf[idf["raceName"].str.contains(
"|".join(listed_racename_list))]["raceName"].unique().tolist()
listed_mapping = {rname: 5 for rname in listed_racename_list}
# それぞれのマッピングを作っておく
def map_race_grade(data: str):
if re.search(r"\(G1\)", data) or re.search(r"\(GI\)", data):
return 8
if re.search(r"\(G2\)", data) or re.search(r"\(GII\)", data):
return 7
if re.search(r"\(G3\)", data) or re.search(r"\(GIII\)", data):
return 6
return None
grade_mapping_dict = {
'4歳未勝利': 0, '4歳新馬': 0, '4歳以上500万下': 1, '4歳500万下': 1, '4歳以上900万下': 2, '4歳以上オープン': 4,
'4歳以上1600万下': 3, '4歳オープン': 4, '4歳未出走': 0, '5歳以上オープン': 4, '4歳900万下': 2, '3歳新馬': 0,
'3歳未勝利': 0, '3歳オープン': 4, '3歳500万下': 1, '3歳未出走': 0, '3歳以上オープン': 4, '3歳900万下': 2,
'2歳新馬': 0, '3歳以上500万下': 1, '3歳以上1000万下': 2, '2歳未勝利': 0, '2歳オープン': 4, '3歳以上1600万下': 3,
'2歳500万下': 1, '4歳以上1000万下': 2, '3歳1000万下': 2, '3歳以上1勝クラス': 1, '3歳以上2勝クラス': 2,
'3歳以上3勝クラス': 3, '2歳1勝クラス': 1, '3歳1勝クラス': 1, '4歳以上1勝クラス': 1, '4歳以上2勝クラス': 2,
'4歳以上3勝クラス': 3
}
# クラスをグレードに置き換える
idf = df["raceName"].map(map_race_grade)
idf = idf[~idf.isna()]
idf2 = df[~df.index.isin(idf.index)]["raceName"].map(listed_mapping)
idf2 = idf2[~idf2.isna()]
df["raceGrade"] = pd.concat([idf, idf2, df[~df.index.isin(idf.index.tolist(
)+idf2.index.tolist())]["raceDetail"].map(grade_mapping_dict)]).astype(int)
再度分け直したので、集計もやり直す
idf = df.copy()
idf["year"] = df["raceDate"].dt.year
idfg = pd.concat(
[
idfg.groupby("year")[["horseId"]].nunique().rename(
columns={"horseId": f"Grade {col}"}) for col, idfg in idf.groupby("raceGrade")
] + [idf.groupby("year")[["horseId"]].nunique().rename(
columns={"horseId": f"Grade ALL"})], axis=1
).fillna(0).convert_dtypes()
idfg["G race"] = idfg[["Grade 6", "Grade 7", "Grade 8"]].sum(axis=1)
idfg["G race rate"] = (100*idfg["G race"]/idfg["Grade ALL"]).round(1)
display(idfg)
sns.heatmap((idfg[idfg.columns[:9]].diff(axis=1).fillna(0)
<= 0).astype(int), annot=True, linewidths=0.01)
plt.show()
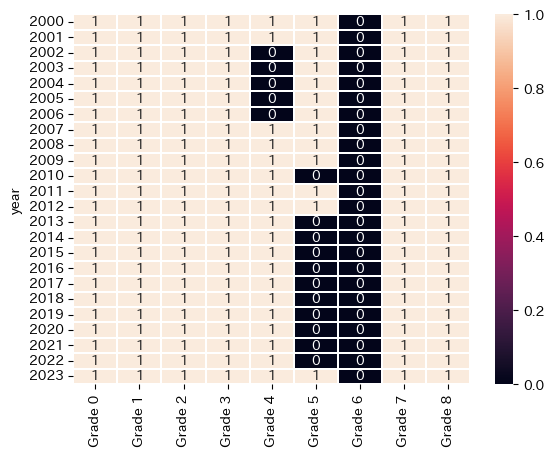
結局、オープンクラスの方が3勝クラスよりも出走数が多い問題は解決していないどころか、悪化したように見える
2-4.オープンクラスが3勝クラスよりも出走馬数が多くなる理由
そもそもレースのクラス分けは獲得賞金や勝利回数だけでなく、格付けが存在しているらしい
その格付けによって新馬戦からいきなり重賞レースへ出走するなどができるようで、1勝するごとに1つグレードが上がるという分けでもないらしい
つまり、新馬・未勝利戦から1勝クラス~3勝クラスからいきなりオープン戦に出るというのは別におかしくないようである
そのため、3勝クラスよりオープンクラスの出走馬数が多いのは、そういうのが原因なのだと考えられる。
2-5.決定事項: モデルの予測対象は2019年以降とする
2019年以降からレース出走条件が変わっていることから、
ファーストモデルでは2018年以降を予測対象としていたが、
現在でも同様の出走条件となっている2019年以降からを予測対象とするように変更する。
2-6.重賞レースに出走できる競走馬の特徴
重賞レースに出走できる馬はかなり能力が高いと思われる。
おまけに、3勝クラスで勝利するなどで順当にクラスを上がってくるだけでなく、
新馬戦からいきなり重賞レースに出走する競走馬などもおり、
重賞レースに出走する競走馬の下積み時代にかなり違いがあると思われる
という訳で重賞レースを走る競走馬について以下の仮説を立てて検証してみる。
- 下積み時代、つまり新馬戦~オープンクラスのレースの出走回数が少ないのでは?
- 血統によって重賞レースに出走できるできないが分かるのでは?
2-6-1.重賞レースに勝利するまでの出走回数の確認
方針としては、
- step0: 1998年以降に生まれた競走馬のみで絞る
- step1: 過去1回以上重賞レースに出走したことのある競走馬に絞って
- step2: 最初に重賞レースに勝利するまでのデータに絞り込み、
- step3: それまでの出走回数を数えることにする
といった感じで調べる
とりあえず、大前提として2000年あたりの出走情報だと2000年より前の年から出走している競走馬が沢山いるため、
事前に1998年以降に生まれた競走馬のみを対象に分析を行う
スクレイピングの段階で競走馬の誕生日を抜き出しているが、
horseIdの上4桁が誕生年になっているので、ここは簡単にその情報を使う
# step0-1: まずは馬の誕生年の情報を追加
df["birthY"] = df["horseId"].str[:4].astype(int)
df["birthY"].sort_values().unique()
# step0-2: 1997年以前生まれの競走馬しかいないレース情報はすべて削除する
filter_raceId_list = df[df["birthY"].isin(
list(range(1998, 2024)))]["raceId"].unique()
dfG = df[df["raceId"].isin(filter_raceId_list)]
dfG["year"] = dfG["raceDate"].dt.year
dfG.groupby("year")[["raceId"]].nunique().T
一旦重賞クラスに出走する競走馬について軽く調べてみたいので、1度でも出走したことのある競走馬のみに絞る
# step1
Ghorse_list = dfG[dfG["raceGrade"].isin([8, 7, 6]) & dfG["birthY"].isin(
list(range(1998, 2024)))]["horseId"].unique()
dfG = dfG[dfG["horseId"].isin(Ghorse_list)]
一旦どんなお馬さんがいるのか確認した中で気になったものを取り上げる
display_columns = ["raceId", "raceDate", "raceName", "raceGrade", "label", "favorite", "odds",
"horseId", "horseName", "stallionName", "bStallionName", "sStallionName", "s2StallionName"]
馬名:ジャックドール
horseId = "2018100274"
df[df["horseId"].isin([horseId])][display_columns]
2023年G1の大阪杯で1着になったジャックドールでみると、2020年12月にデビューしてから
G1勝利するまでの2年5カ月間で12レース出場し7勝5敗と実力を遺憾なく発揮している
デビュー時から人気も高いという素晴らしいサラブレッドぶり
どうして下積みとして下位クラスをこんなにも出場させられていたのか分からないほど
もしかしたら、競走馬の中にも成長度合いによって下積みを長くしたり等があるのかもしれない
馬名:ドウデュース
horseId = "2019105283"
df[df["horseId"].isin([horseId])][display_columns]
早い段階で重賞クラスで活躍している競走馬も見てみると、
デビュー戦時点で1番人気、オッズ1.7、堂々の1着から
2021年朝日杯フューチュリティステークスのG1制覇まで3戦全勝の爆走ぶり
父にはハーツクライを引っ提げ、現在も活躍中のG1三冠馬であるドウデュース
成績を見るとあまりにも化け物
5歳馬になった今でもオッズがほぼ10を上回らない人気ぶりという早くから頭角を現すものもいる
重賞クラスに1度でも勝利した競走馬のみのデータに絞る
# step2: 処理が難しいがこういうのは全てgroupbyが何とかしてくれる
group_df = dfG.groupby("horseId")[["label", "raceGrade"]].filter(
lambda group: group[group["raceGrade"].isin([6, 7, 8])]["label"].isin([1]).any())
dfG1 = dfG.loc[group_df.index]
# 一応1998年生まれ以降の競走馬のみ残す
dfG1 = dfG1[dfG1["birthY"].isin(list(range(1998, 2024)))]
dfG1["horseId"].nunique(), round(
100*dfG1["horseId"].nunique()/df["horseId"].nunique(), 3)
24年間で1486頭しかいない。全体の競走馬の中でも1.297%程度しかいない。
想像よりも重賞クラスで勝つのは厳しいようだ
(そもそも重賞クラスのレース数が少ないから当たり前ではある)
最後に初めて重賞クラスで勝利するまでの情報に絞り込む
# step3: こういう場合は、Gwinカラムを追加して、
# 重賞に勝利した行にフラグを立てて、groupbyからのcumsumしてあげる
dfG1["Gwin"] = (dfG1["label"].isin([1]) &
dfG1["raceGrade"].isin([6, 7, 8])).astype(int)
dfG1["Gwin"] = dfG1.groupby("horseId")["Gwin"].cumsum()
# 最後にGwinが0の行だけ取り出せばOK
dfG1 = dfG1[dfG1["Gwin"].isin([0])]
# それでは実際にカウントしてみる
dfG_cnt = dfG1.groupby("horseId")["horseId"].count()
dfG_cnt.describe()
集計結果から、平均して10レース弱で重賞クラスに勝利しているようで、
中央値としても7レースであることから、特段大きな偏りがないように見える
2-6-2.G1, G2, G3に勝利したお馬さんが重賞クラスに勝利するまでの平均出走回数
# さっきまでの処理を再利用
def count_raceNum_for_G(target: list[int], firstwin=[6, 7, 8], mode=True, dfG=dfG):
group_df = dfG.groupby("horseId")[["label", "raceGrade"]].filter(
lambda group: group[group["raceGrade"].isin(target)]["label"].isin([1]).any())
dfG1 = dfG.loc[group_df.index][["horseId", "birthY", "raceGrade", "label"]]
dfG1 = dfG1[dfG1["birthY"].isin(list(range(1998, 2024)))]
dfG1["win"] = (dfG1["label"].isin([1]) &
dfG1["raceGrade"].isin(firstwin)).astype(int)
dfG1["win"] = dfG1.groupby("horseId")["win"].cumsum()
win_horseId_list = []
dfG2 = dfG1[dfG1["win"].isin([0])]
if 0 in target:
win_horseId_list = list(
set(dfG1["horseId"].unique()) - set(dfG2["horseId"].unique()))
dfG_cnt = dfG2.groupby("horseId")["horseId"].count()
dfG_cnt = pd.concat([dfG_cnt, pd.Series(0, index=win_horseId_list)])
if mode:
return dfG_cnt.describe()
return dfG_cnt
pd.concat([count_raceNum_for_G(
[6+idx]).rename(f"G{3-idx}") for idx in range(3)], axis=1).T.convert_dtypes()
平均出走回数でみると、G3 < G2 < G1の順で勝つまでのレース数が少なくなっていく
つまり、G1で勝てるお馬さんは早い段階からその実力が出ることが容易に想像できる。
G1勝利馬で見ると、中央値ですら重賞クラスに勝利するまで4レースしか走らない。
とはいえ、G2やG3で勝つ馬もだいたい6から8レース走ってから重賞クラスに勝利している。
# 馬の平均出走回数
dfG.groupby("horseId")[["raceId"]].count().describe().T
出走情報全体で見てもお馬さんの平均出走回数は21回とかなり走っている。
そう言った中で、8レースほどで重賞クラスに勝利できるかどうかでそのお馬さんの実力が分かりそうだ
2-7.重賞クラス勝利平均出走回数の上位25%と下位25%の父と母父の分布確認
2-7-1.G1, G2, G3を制した種牡馬産駒の平均出走回数で調べる
すこし気になった、成長度合いのスピードが血統によって違いが出ているのではないかという点
簡単に種牡馬の産駒数を数える
# G1,G2,G3に勝利した競走馬を分析
pickup = 15
threash = 0.25
dflist = []
multiColumns = []
# 2019年以降に出走したことのある競走馬のみに絞る
dfG2 = dfG[dfG["horseId"].isin(dfG[dfG["raceDate"].dt.year.isin(
list(range(2019, 2024)))]["horseId"].unique())]
for g, idfG in dfG2.groupby(["field", "dist_cat"]):
# field, dist_catごとに出走したことのある競走馬に対して、
# G1, G2, G3で勝利したことのある競走馬
dfG_cnt = count_raceNum_for_G(
list(range(9)), [6, 7, 8], mode=False, dfG=idfG).rename(f"Grace")
upperhorse = dfG_cnt[dfG_cnt.quantile(threash) >= dfG_cnt].index.tolist()
lowerhorse = dfG_cnt[dfG_cnt.quantile(1-threash) < dfG_cnt].index.tolist()
if len(upperhorse) == 0:
upperhorse = dfG_cnt[dfG_cnt.isin([dfG_cnt.min()])].index.tolist()
if len(lowerhorse) == 0:
lowerhorse = dfG_cnt[dfG_cnt.isin([dfG_cnt.max()])].index.tolist()
dfGhigh25 = dfG2[dfG2["horseId"].isin(upperhorse)]
dfGlow25 = dfG2[dfG2["horseId"].isin(lowerhorse)]
# 種牡馬
dftarget = dfstallion
dflist += [dftarget[dftarget["horseId"].isin(dfGhigh25["horseId"].unique())]["GenName"].value_counts().sort_values(
ascending=False).head(pickup).reset_index().apply(lambda x: ", ".join([str(x) for x in x.tolist()]), axis=1)]
dflist += [dftarget[dftarget["horseId"].isin(dfGlow25["horseId"].unique())]["GenName"].value_counts().sort_values(
ascending=False).head(pickup).reset_index().apply(lambda x: ", ".join([str(x) for x in x.tolist()]), axis=1)]
multiColumns += [[g[0], f"high{int(threash*100)}%", g[1]],
[g[0], f"low{int(threash*100)}%", g[1]]]
threash_col = [f"high{int(threash*100)}%", f"low{int(threash*100)}%"]
idfgen = pd.concat(dflist, axis=1).rename(
index=lambda idx: f"{1+idx}位").fillna("")
idfgen.columns = pd.MultiIndex.from_tuples(multiColumns)
idfgen = idfgen.T.sort_index(key=lambda x: [({"ダ": 0, "芝": 1, f"high{int(threash*100)}%": 0} | {
k: n for n, k in enumerate("SMILE")}).get(ix, 1) for ix in x])
idfgen[idfgen.columns[:5]]
確認してみると、芝ではどちらもディープインパクトが目立っており、他の種牡馬で見ても大した違いはないように見える。
ダートの方では、早く結果を残すものとそうでないもので、違いが出ているがとはいえ産駒数が少ないのもあり、誤差の範囲にも見える
みんな大好きワードクラウドでも出してみましょう
colormap = "RdYlBu"
# linux系なら以下あたりにフォントファイルがあるかも?調べてもらう方が早いと思います。
# font_path="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf"
# Windowsの人は以下あたりにあるかと
font_path = "C:/Windows/Fonts/meiryo.ttc"
for field in ["ダ", "芝"]:
idfg = idfgen.loc[field]
ncols = len(idfg.loc[idfg.index[0][0]])
nrows = len(threash_col)
plt.figure(figsize=(27, 9))
cnt = 1
for row, idx in enumerate(threash_col, start=1):
for cidx in "SMILE"[:ncols]:
word_list = []
for word in idfg.loc[(idx, cidx)].tolist():
if word == "":
break
word_list += [word.split(", ")[0]]*int(word.split(", ")[1])
if len(word_list) == 0:
break
random.shuffle(word_list)
plt.subplot(nrows, ncols, cnt)
wordcloud = WordCloud(
background_color="gray",
width=800,
height=800,
font_path=font_path,
colormap=colormap,
).generate(" ".join(word_list))
plt.imshow(wordcloud, interpolation="bilinear")
plt.title(", ".join([field, idx, cidx]))
plt.axis("off")
cnt += 1
plt.show()


詳細は述べません、感じてください。
2-7-2.G1, G2, G3を制した母父産駒の平均出走回数で調べる
# G1,G2,G3に勝利した競走馬を分析
pickup = 15
threash = 0.25
dflist = []
multiColumns = []
# 2019年以降に出走したことのある競走馬のみに絞る
dfG2 = dfG[dfG["horseId"].isin(dfG[dfG["raceDate"].dt.year.isin(
list(range(2019, 2024)))]["horseId"].unique())]
for g, idfG in dfG2.groupby(["field", "dist_cat"]):
# field, dist_catごとに出走したことのある競走馬に対して、
# G1, G2, G3で勝利したことのある競走馬
dfG_cnt = count_raceNum_for_G(
list(range(9)), [6, 7, 8], mode=False, dfG=idfG).rename(f"Grace")
upperhorse = dfG_cnt[dfG_cnt.quantile(threash) >= dfG_cnt].index.tolist()
lowerhorse = dfG_cnt[dfG_cnt.quantile(1-threash) < dfG_cnt].index.tolist()
if len(upperhorse) == 0:
upperhorse = dfG_cnt[dfG_cnt.isin([dfG_cnt.min()])].index.tolist()
if len(lowerhorse) == 0:
lowerhorse = dfG_cnt[dfG_cnt.isin([dfG_cnt.max()])].index.tolist()
dfGhigh25 = dfG2[dfG2["horseId"].isin(upperhorse)]
dfGlow25 = dfG2[dfG2["horseId"].isin(lowerhorse)]
# 母の種牡馬で見る
dftarget = dfbStallion
dflist += [dftarget[dftarget["horseId"].isin(dfGhigh25["horseId"].unique())]["GenName"].value_counts().sort_values(
ascending=False).head(pickup).reset_index().apply(lambda x: ", ".join([str(x) for x in x.tolist()]), axis=1)]
dflist += [dftarget[dftarget["horseId"].isin(dfGlow25["horseId"].unique())]["GenName"].value_counts().sort_values(
ascending=False).head(pickup).reset_index().apply(lambda x: ", ".join([str(x) for x in x.tolist()]), axis=1)]
multiColumns += [[g[0], f"high{int(threash*100)}%", g[1]],
[g[0], f"low{int(threash*100)}%", g[1]]]
threash_col = [f"high{int(threash*100)}%", f"low{int(threash*100)}%"]
idfgen = pd.concat(dflist, axis=1).rename(
index=lambda idx: f"{1+idx}位").fillna("")
idfgen.columns = pd.MultiIndex.from_tuples(multiColumns)
idfgen = idfgen.T.sort_index(key=lambda x: [({"ダ": 0, "芝": 1, f"high{int(threash*100)}%": 0} | {
k: n for n, k in enumerate("SMILE")}).get(ix, 1) for ix in x])
idfgen[idfgen.columns[:5]]
ダートは種牡馬のときと同様に産駒数も少なく上位, 下位での違いが見られないが、
芝の方では上位ではディープインパクトが、下位ではサンデーサイレンスが目立つ
サンデーサイレンスの血を持つ母親が単純に多いだけの可能性もあるが、
とはいえほとんどの距離カテゴリでサンデーサイレンスが多い点から、
母父にサンデーサイレンスを持つ血統は序盤の活躍は少ない可能性がある。
また、上位で見るとそのほとんどがディープインパクトであることから、
ディープインパクトの種牡馬であるサンデーサイレンスの特徴は薄れ、
逆に早熟の特徴が母父にディープインパクトの血を持つ産駒には見られるようである
for field in ["ダ", "芝"]:
idfg = idfgen.loc[field]
ncols = len(idfg.loc[idfg.index[0][0]])
nrows = len(threash_col)
plt.figure(figsize=(27, 9))
cnt = 1
for row, idx in enumerate(threash_col, start=1):
for cidx in "SMILE"[:ncols]:
word_list = []
for word in idfg.loc[(idx, cidx)].tolist():
if word == "":
break
word_list += [word.split(", ")[0]]*int(word.split(", ")[1])
if len(word_list) == 0:
break
random.shuffle(word_list)
plt.subplot(nrows, ncols, cnt)
wordcloud = WordCloud(
background_color="gray",
width=800,
height=800,
font_path=font_path,
colormap=colormap,
).generate(" ".join(word_list))
plt.imshow(wordcloud, interpolation="bilinear")
plt.title(", ".join([field, idx, cidx]))
plt.axis("off")
cnt += 1
plt.show()


2-8.まとめ
2-8-1.分かったこと
- 2019年以降からレースの出走条件が変わり、上位クラスに出走していた古馬は下位クラスに出走できなくなったこととリステッドクラスが導入された
- オープンクラスは、3勝クラスまでを順番に勝ち上がってから出場する必要はなく、運営が認めれば新馬戦を勝利後にいきなり重賞レース参加することができる
- 実際に重賞クラスに勝利できる競走馬はその半分は8レース以内にその実力が現れることが分かった
- 芝とダートで特定の血統を持つ産駒に成長度合いと成績に関係があるか調べたところ、芝の重賞クラスに勝利した競走馬の中で母父に限りそのような関係がありそうだと分かった。
2-8-2.決定事項
- モデルの予測対象は2019年以降のデータとする
- レースを9段階にグレード分けする
2-8-3.次回やること
- 血統と単勝・連対・複勝率の関係
- 芝とダートでモデルを分けるべきか否か
- どこまで血統を考慮すれば良いか確認


コメント