
はじめに
本シリーズでは、動画として解説しなかったロードマップ3のファーストモデルの開発で詳細な部分を解説しています。
ロードマップ2で決定したモデル作成時の前提一覧については以下のページを参照ください。

競馬予想プログラムソフト開発の制作過程動画リスト
ファーストモデルの概要
これから作成するすべてのモデルにおいて、最低限こいつにだけは勝つ必要があるベースラインとなるモデルがファーストモデルとなります。
ベース前処理を施した競馬データを使って、モデルの学習をし所定の期間のレースデータを予測した結果をもとにパフォーマンスを評価します。
その評価を比べることでモデルの優劣を決めます。比べ方はまた別途で解説しようかと考えています。
学習時の前提
詳しくはNoteBookで解説していますが、以下のような学習・検証・テストのデータセットを作成してモデルを作成しています。
以下イメージ図です。
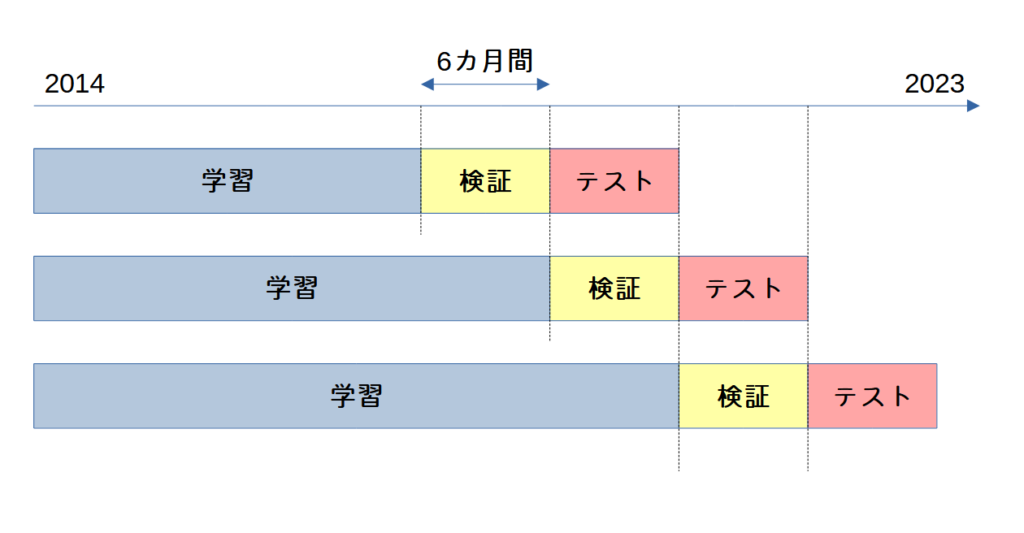
画像のように検証とテストのデータセットの期間を半年ごとにシフトして検証データ以前の期間を学習データとしてモデルを学習しています。
半年ごとに区切った理由としては新馬の影響を考慮してです。毎年1月から3歳馬の新馬が6月から2歳馬の新馬が出走し始めるため、データの性質が変わってしまうことを危惧しての配慮です。
正直、6月から翌年5月までを1期間として判断するやり方もあるので、如何ともしがたいです。いったん半年ごとに区切るやり方でベースラインではモデルを作ろうと思います。
テスト期間は2018年から2023年までとするので、データセットはテストデータを2018年上期 → 2018年下期 → 2019年上期 → ・・・ → 2023年下期と半年ごとにシフトして作っていくため、全部で12個のモデルができると思ってください。
ここの期間指定も12モデルも作るのが結構大変になってくるかもなので、もしかしたらもう少し期間を狭めるかも・・・
競馬自体2019年から降級制度がなくなったりと一つの転換点になっているようでもあるので、なるべくその前後期間からパフォーマンスを評価したいという気持ちもあり、、ここはトライ&エラーになるかと。
モデル概要
使用する機械学習モデルは、lightGBM(ver4.1.0)を使用します。以下モデルの設定です。
| 設定項目 | 説明 |
| モデル | lightGBM |
| タスク | 2値分類 |
| 問題設定 | 3着以内に入るかどうか |
| 使用年度 | 2014年~2023年データ |
| 予測年度 | 2018年~2023年データ |
| 説明変数 | オッズや人気を含む18項目 詳細はNotebook参照 |
学習結果
どの人気に賭けているか?
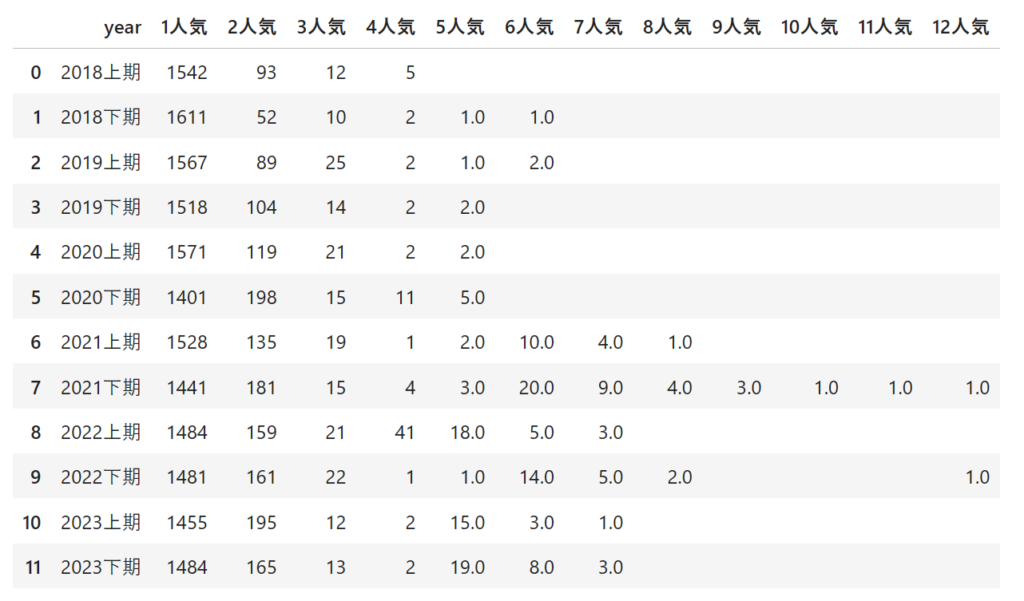
説明変数にオッズを入れてるので当然ですがほとんどが1番人気に賭けています。
オッズには市場参加者が考えているすべてのファクターが含まれていると考えれば、オッズを頼りに学習するというのは致し方無い結果でしょう。
特徴量重要度
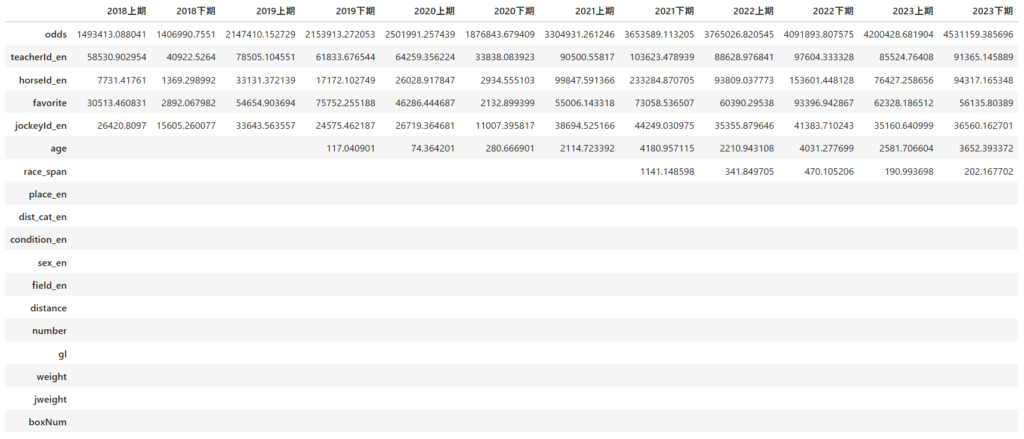
空欄は0だったものです。
結果をみるとオッズが非常に高く出ているので想定通りではありますが、意外だったのが調教師や騎手の特徴量もそれなりにあるというところです。
オッズにそういった調教師や騎手の特徴も織り込まれていると思っていたので、特徴量重要度としてはほとんど0に近いものになると思っていました。しかし、結果を見るとオッズに対して2桁程度の差しかなく、オッズだけが勝利の決定要因にならない可能性があるのかもしれないという印象を持ちました。
つまり、オッズ以外の特徴量を用いてもオッズを入れた場合と同等のパフォーマンスは最低限目指せそうだということです。(勘です。検証もするかどうか分かりません)
とはいえ、オッズを特徴量として入れないまでも何かしらの形でオッズを反映したモデルを作らなければならないことは確かなので、今後もオッズの特徴量は入れ続けるべきだと考えます。
予測結果と勝率のオッズグラフ
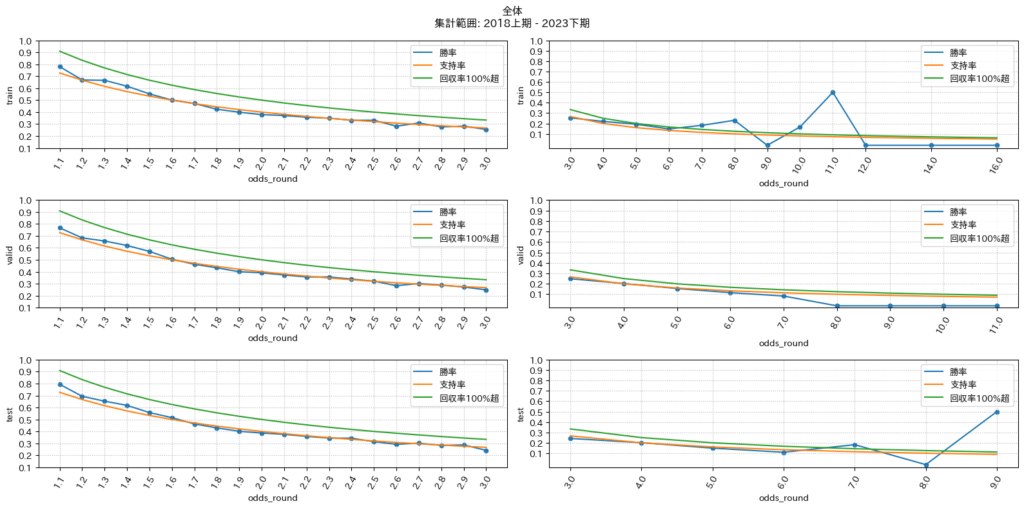
上段から学習データ、検証データ、テストデータとなっており、横軸がオッズで縦軸が勝率を表しています。青線がモデルの予測結果に対する勝率であり、オレンジ色がオッズに基づく支持率を表し、緑線が各オッズに関して回収率が100%超えるための勝率を表しています。
グラフの見方は単順に、最低限モデルのパフォーマンスである青色の線が支持率の線をほとんどのオッズで超えていること、理想は青色の線が回収率100%超えとなる緑線をほとんどのオッズで超えていることになります。
グラフをみると学習段階でほとんどのオッズ帯で青色の線がオレンジ色の線に沿っている結果になっていることからオッズが一桁台の競走馬に賭け続けていることが分かります。オッズを特徴量として入れているので想定通りの結果と言えるでしょう。
ファーストモデル開発時のソースコード
以下にファーストモデル開発時のソースコードを載せます。モデルの設計方針からモデル作成、パフォーマンスの確認まで行っています。今後もこのようなNotebook形式で同じような流れで分析を進めることになるかと思います。
Notebookの最終更新:2024年3月28日
ファーストモデルについて¶
モデルの目的¶
すべての基準となるモデルです。誰もが最初にやるであろう手法でモデルを作成します。
意図としては、共通した基準を定めておくことで、セカンドモデル以降で基準を最低限超えているかどうかで、モデル改編の方針が有効であるかの判断ができる。
ベースラインとしてこのモデルのパフォーマンスを評価する。
モデル方針¶
ベースとなるモデルの設計方針です。
ベースモデル¶
以下の設定でモデルを作成します。
- 機械学習モデル: lightGBM
- 目的関数: 2値分類
- 説明変数: オッズや人気を含む出走前公開情報(前N走は未使用)
- 予測対象: 対象の馬が3着以内に入賞するかどうか
- 使用期間: 2010年~2023年
- 予測期間: 2018年~2023年
学習方針¶
ここでは、以下のような方針で2018年から2023年までのデータを予測する
例:2018年を予測する場合
予測範囲を上期と下期で分ける
- 上期の場合
学習対象の期間を2014年1月~2017年の6月までとし、
検証対象の期間を2017年の7月~2017年の12月までとする。
予測対象の期間を2018年の1月~2018年の6月までとする - 下期の場合
学習対象の期間を2014年1月~2017年の12月までとし、
検証対象の期間を2018年の1月~2018年の6月までとする。
予測対象の期間を2018年の7月~2018年の12月までとする
以上のような切り分けで、学習データと検証データを分けたデータセットで2018年予測用モデルを作成
作成したモデルで、予測対象期間のデータを推論する。
これを、2018年から2023年まで学習期間を増やしながら推論する。
モデル作成¶
0.必要なモジュールのインポート¶
一部有料ソースを含んでいます。同じ条件で競馬予想プログラムソフトを開発したい方は、宜しければソースをお買い求めください。
公開ソース一覧:https://keiba-ds-lab.com/bookers-article-lists/
import matplotlib.pyplot as plt
import japanize_matplotlib
import warnings
import numpy as np
import pandas as pd
import tqdm
import pathlib
import datetime
import lightgbm as lgbm
import sys
sys.path.append(".")
from src.data_manager.preprocess_tools import DataPreProcessor # noqa
from src.data_manager.data_loader import DataLoader # noqa
warnings.filterwarnings("ignore")
# 各種インスタンスの作成
data_loader = DataLoader(2010, 2023)
dataPreP = DataPreProcessor()
1.競馬データのロードと前処理の実行¶
ロードマップ3-1で作成した前処理モジュールを使って、競馬データを加工する。
df = data_loader.load_racedata()
df = dataPreP.exec_pipeline(df)
2024-03-28 12:00:41.395 | INFO | src.data_manager.data_loader:load_racedata:23 - Get Year Range: 2010 -> 2023. 2024-03-28 12:00:41.397 | INFO | src.data_manager.data_loader:load_racedata:24 - Loading Race Info ... 2024-03-28 12:00:41.842 | INFO | src.data_manager.data_loader:load_racedata:26 - Loading Race Data ... 2024-03-28 12:00:51.709 | INFO | src.data_manager.data_loader:load_racedata:28 - Merging Race Info and Race Data ...
2024-03-28 12:00:53.221 | INFO | src.data_manager.preprocess_tools:__0_check_use_save_checkpoints:34 - Start PreProcess #0 ... 2024-03-28 12:00:53.224 | INFO | src.data_manager.preprocess_tools:__1_exec_all_sub_prep1:37 - Start PreProcess #1 ... 2024-03-28 12:00:57.179 | INFO | src.data_manager.preprocess_tools:__2_exec_all_sub_prep2:39 - Start PreProcess #2 ... 2024-03-28 12:01:01.567 | INFO | src.data_manager.preprocess_tools:__3_convert_type_str_to_number:41 - Start PreProcess #3 ... 2024-03-28 12:01:04.147 | INFO | src.data_manager.preprocess_tools:__4_drop_or_fillin_none_data:43 - Start PreProcess #4 ... 2024-03-28 12:01:06.416 | INFO | src.data_manager.preprocess_tools:__5_exec_all_sub_prep5:45 - Start PreProcess #5 ... 2024-03-28 12:01:21.257 | INFO | src.data_manager.preprocess_tools:__6_convert_label_to_rate_info:47 - Start PreProcess #6 ... 2024-03-28 12:01:33.551 | INFO | src.data_manager.preprocess_tools:__7_convert_distance_to_smile:49 - Start PreProcess #7 ... 2024-03-28 12:01:33.742 | INFO | src.data_manager.preprocess_tools:__8_category_encoding:51 - Start PreProcess #8 ...
2.モデル作成用に学習する説明変数と予測する目的変数の準備¶
説明変数は、オッズや人気を含む出走前公開情報(前N走や血統情報は未使用)を用いて、
予測対象は、対象の馬が3着以内に入賞するかどうかを用いる
# 説明変数
feature_columns = [
'distance',
'number',
'boxNum',
'odds',
'favorite',
'age',
'jweight',
'weight',
'gl',
'race_span',
] + dataPreP.encoding_columns
# 目的変数
objective_column = "label_in3"
df["label_in3"] = df["label"].isin([1, 2, 3]).astype(int)
# 説明変数の中に、object型がいないことを確認
df[feature_columns].info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 659571 entries, 0 to 659570 Data columns (total 18 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 distance 659571 non-null int64 1 number 659571 non-null int32 2 boxNum 659571 non-null int64 3 odds 659571 non-null float64 4 favorite 659571 non-null int64 5 age 659571 non-null int64 6 jweight 659571 non-null float64 7 weight 659571 non-null float64 8 gl 659571 non-null float64 9 race_span 588285 non-null float64 10 place_en 659571 non-null category 11 field_en 659571 non-null category 12 sex_en 659571 non-null category 13 condition_en 659571 non-null category 14 jockeyId_en 659571 non-null category 15 teacherId_en 659571 non-null category 16 dist_cat_en 659571 non-null category 17 horseId_en 659571 non-null category dtypes: category(8), float64(5), int32(1), int64(4) memory usage: 58.6 MB
3.学習・テスト用データの準備¶
start_year = 2010
split_year = 2014
# 実際の競馬予想プログラムソフトでは、ここはクラス化する。
def get_query_group(df: pd.DataFrame):
temp_df = df['raceId'].value_counts().rename_axis('query').reset_index(name='query_count').sort_values('query')
return temp_df['query_count'].values
dataset_mapping: dict[int, dict[str, pd.DataFrame]] = {}
for target_year in range(2018, 2024):
train_data_range = pd.date_range(datetime.date(split_year, 1, 1), datetime.date(target_year-1, 6, 30))
valid_data_range = pd.date_range(datetime.date(target_year-1, 7, 1), datetime.date(target_year-1, 12, 31))
test_data_range = pd.date_range(datetime.date(target_year, 1, 1), datetime.date(target_year, 6, 30))
dftrain = df[df["raceDate"].isin(train_data_range) & ~df["rough_race"].astype(bool)]
dfvalid = df[df["raceDate"].isin(valid_data_range) & ~df["rough_race"].astype(bool)]
dftest = df[df["raceDate"].isin(test_data_range) & ~df["rough_race"].astype(bool)]
dataset_mapping[f"{target_year}上期"] = {
"train": dftrain,
"valid": dfvalid,
"test": dftest
}
train_data_range = pd.date_range(datetime.date(split_year, 1, 1), datetime.date(target_year-1, 12, 31))
valid_data_range = pd.date_range(datetime.date(target_year, 1, 1), datetime.date(target_year, 6, 30))
test_data_range = pd.date_range(datetime.date(target_year, 7, 1), datetime.date(target_year, 12, 31))
dftrain = df[df["raceDate"].isin(train_data_range) & ~df["rough_race"].astype(bool)]
dfvalid = df[df["raceDate"].isin(valid_data_range) & ~df["rough_race"].astype(bool)]
dftest = df[df["raceDate"].isin(test_data_range) & ~df["rough_race"].astype(bool)]
dataset_mapping[f"{target_year}下期"] = {
"train": dftrain,
"valid": dfvalid,
"test": dftest
}
4.モデルの作成¶
当然ながら、モデルは2018年版~2023年版の合計6モデルできる。
# ここも競馬予想プログラムソフトでは、クラス化させる
# lightGBM用のモデルパラメータ
# パラメータ自体は適当にする。あまりこだわっても泥沼になるので
params = {
'boosting_type': 'gbdt',
# 二値分類
'objective': 'binary',
'metric': 'auc',
'verbose': 1,
'seed': 77777,
'learning_rate': 0.01,
"n_estimators": 10000,
}
model_dict: dict[int, lgbm.Booster] = {}
dfimp_dict: dict[int, pd.DataFrame] = {}
for target_year in dataset_mapping.keys():
dftrain, dfvalid, dftest = dataset_mapping[target_year].values()
train_dataset = lgbm.Dataset(
dftrain[feature_columns], dftrain[objective_column])
valid_dataset = lgbm.Dataset(
dfvalid[feature_columns], dfvalid[objective_column])
test_dataset = lgbm.Dataset(
dftest[feature_columns], dftest[objective_column])
model = lgbm.train(
params,
train_dataset,
valid_sets=[
train_dataset,
valid_dataset,
],
callbacks=[
lgbm.early_stopping(stopping_rounds=500, verbose=True,),
lgbm.log_evaluation(100)
],
)
dfimp = pd.DataFrame(
data={
"split": model.feature_importance(importance_type="split"),
"gain": model.feature_importance(importance_type="gain")
},
index=feature_columns
).sort_values("gain", ascending=False)
dfimp_dict[target_year] = dfimp.copy()
for idf in [dftrain, dfvalid, dftest]:
idf["pred_prob"] = model.predict(
idf[feature_columns],
num_iteration=model.best_iteration
)
idf["pred"] = idf.sort_values("odds", ascending=True).groupby(
"raceId")["pred_prob"].rank(ascending=False, method="first")
idf["pred"] = ((idf["pred_prob"] > idf["pred_prob"].quantile(0.5)) & idf["pred"].isin([1])).astype(int)
print("finish!", target_year)
[LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 34810, number of negative: 133356 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.014823 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 18849 [LightGBM] [Info] Number of data points in the train set: 168166, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.206998 -> initscore=-1.343118 [LightGBM] [Info] Start training from score -1.343118 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.824922 valid_1's auc: 0.815281 [200] training's auc: 0.832364 valid_1's auc: 0.814942 [300] training's auc: 0.840124 valid_1's auc: 0.813794 [400] training's auc: 0.847672 valid_1's auc: 0.8122 [500] training's auc: 0.853341 valid_1's auc: 0.81094 Early stopping, best iteration is: [98] training's auc: 0.824781 valid_1's auc: 0.815309 finish! 2018上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 39929, number of negative: 152032 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.014332 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 20753 [LightGBM] [Info] Number of data points in the train set: 191961, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.208006 -> initscore=-1.336988 [LightGBM] [Info] Start training from score -1.336988 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.824517 valid_1's auc: 0.821978 [200] training's auc: 0.831623 valid_1's auc: 0.821925 [300] training's auc: 0.8388 valid_1's auc: 0.821021 [400] training's auc: 0.845942 valid_1's auc: 0.81972 [500] training's auc: 0.851262 valid_1's auc: 0.818537 Early stopping, best iteration is: [60] training's auc: 0.821836 valid_1's auc: 0.822222 finish! 2018下期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 44889, number of negative: 170915 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.017331 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 22217 [LightGBM] [Info] Number of data points in the train set: 215804, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.208008 -> initscore=-1.336974 [LightGBM] [Info] Start training from score -1.336974 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.824609 valid_1's auc: 0.816205 [200] training's auc: 0.831139 valid_1's auc: 0.816608 [300] training's auc: 0.838008 valid_1's auc: 0.816108 [400] training's auc: 0.844993 valid_1's auc: 0.815644 [500] training's auc: 0.849992 valid_1's auc: 0.814961 [600] training's auc: 0.853963 valid_1's auc: 0.814374 Early stopping, best iteration is: [137] training's auc: 0.826974 valid_1's auc: 0.816743 finish! 2019上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 49917, number of negative: 188753 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.016272 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 22950 [LightGBM] [Info] Number of data points in the train set: 238670, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.209147 -> initscore=-1.330078 [LightGBM] [Info] Start training from score -1.330078 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.824327 valid_1's auc: 0.817385 [200] training's auc: 0.830303 valid_1's auc: 0.817154 [300] training's auc: 0.836927 valid_1's auc: 0.816576 [400] training's auc: 0.843491 valid_1's auc: 0.815326 [500] training's auc: 0.848205 valid_1's auc: 0.814346 [600] training's auc: 0.851867 valid_1's auc: 0.813308 Early stopping, best iteration is: [100] training's auc: 0.824327 valid_1's auc: 0.817385 finish! 2019下期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 54969, number of negative: 207110 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.019919 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 23979 [LightGBM] [Info] Number of data points in the train set: 262079, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.209742 -> initscore=-1.326481 [LightGBM] [Info] Start training from score -1.326481 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.823846 valid_1's auc: 0.808832 [200] training's auc: 0.82956 valid_1's auc: 0.80884 [300] training's auc: 0.835811 valid_1's auc: 0.808177 [400] training's auc: 0.841882 valid_1's auc: 0.807239 [500] training's auc: 0.846424 valid_1's auc: 0.80635 [600] training's auc: 0.85 valid_1's auc: 0.805499 Early stopping, best iteration is: [111] training's auc: 0.824523 valid_1's auc: 0.808954 finish! 2020上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 59886, number of negative: 224357 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.022491 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 24438 [LightGBM] [Info] Number of data points in the train set: 284243, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.210686 -> initscore=-1.320796 [LightGBM] [Info] Start training from score -1.320796 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.822943 valid_1's auc: 0.805599 [200] training's auc: 0.828336 valid_1's auc: 0.805566 [300] training's auc: 0.834475 valid_1's auc: 0.805235 [400] training's auc: 0.840426 valid_1's auc: 0.804453 [500] training's auc: 0.844969 valid_1's auc: 0.803805 Early stopping, best iteration is: [48] training's auc: 0.820561 valid_1's auc: 0.805655 finish! 2020下期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 65023, number of negative: 243156 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.021886 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 25276 [LightGBM] [Info] Number of data points in the train set: 308179, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.210991 -> initscore=-1.318962 [LightGBM] [Info] Start training from score -1.318962 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.821859 valid_1's auc: 0.806258 [200] training's auc: 0.826982 valid_1's auc: 0.806333 [300] training's auc: 0.833003 valid_1's auc: 0.805915 [400] training's auc: 0.838697 valid_1's auc: 0.804989 [500] training's auc: 0.843182 valid_1's auc: 0.804131 [600] training's auc: 0.846563 valid_1's auc: 0.803238 Early stopping, best iteration is: [185] training's auc: 0.8262 valid_1's auc: 0.806393 finish! 2021上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 69874, number of negative: 260687 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.026620 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 25591 [LightGBM] [Info] Number of data points in the train set: 330561, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.211380 -> initscore=-1.316627 [LightGBM] [Info] Start training from score -1.316627 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.820972 valid_1's auc: 0.816423 [200] training's auc: 0.82596 valid_1's auc: 0.816391 [300] training's auc: 0.831757 valid_1's auc: 0.816366 [400] training's auc: 0.837271 valid_1's auc: 0.815495 [500] training's auc: 0.841652 valid_1's auc: 0.814492 [600] training's auc: 0.84499 valid_1's auc: 0.81357 [700] training's auc: 0.847908 valid_1's auc: 0.812732 Early stopping, best iteration is: [269] training's auc: 0.829938 valid_1's auc: 0.816484 finish! 2021下期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 74932, number of negative: 279100 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.023861 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 26326 [LightGBM] [Info] Number of data points in the train set: 354032, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.211653 -> initscore=-1.314989 [LightGBM] [Info] Start training from score -1.314989 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.820814 valid_1's auc: 0.809706 [200] training's auc: 0.825606 valid_1's auc: 0.809922 [300] training's auc: 0.831189 valid_1's auc: 0.809056 [400] training's auc: 0.836426 valid_1's auc: 0.80808 [500] training's auc: 0.840578 valid_1's auc: 0.807362 [600] training's auc: 0.843807 valid_1's auc: 0.806668 Early stopping, best iteration is: [174] training's auc: 0.824298 valid_1's auc: 0.810015 finish! 2022上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 79860, number of negative: 296698 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.023653 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 26544 [LightGBM] [Info] Number of data points in the train set: 376558, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.212079 -> initscore=-1.312440 [LightGBM] [Info] Start training from score -1.312440 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.820224 valid_1's auc: 0.818594 [200] training's auc: 0.824841 valid_1's auc: 0.818811 [300] training's auc: 0.830286 valid_1's auc: 0.818688 [400] training's auc: 0.835381 valid_1's auc: 0.818161 [500] training's auc: 0.839455 valid_1's auc: 0.817531 [600] training's auc: 0.842626 valid_1's auc: 0.816992 [700] training's auc: 0.845504 valid_1's auc: 0.816505 Early stopping, best iteration is: [216] training's auc: 0.82566 valid_1's auc: 0.818836 finish! 2022下期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 84853, number of negative: 314728 [LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.008713 seconds. You can set `force_row_wise=true` to remove the overhead. And if memory is not enough, you can set `force_col_wise=true`. [LightGBM] [Info] Total Bins 27179 [LightGBM] [Info] Number of data points in the train set: 399581, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.212355 -> initscore=-1.310788 [LightGBM] [Info] Start training from score -1.310788 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.820212 valid_1's auc: 0.815209 [200] training's auc: 0.824587 valid_1's auc: 0.815299 [300] training's auc: 0.829851 valid_1's auc: 0.815334 [400] training's auc: 0.834813 valid_1's auc: 0.814842 [500] training's auc: 0.838694 valid_1's auc: 0.814349 [600] training's auc: 0.841916 valid_1's auc: 0.813653 Early stopping, best iteration is: [159] training's auc: 0.822708 valid_1's auc: 0.815399 finish! 2023上期 [LightGBM] [Warning] Categorical features with more bins than the configured maximum bin number found. [LightGBM] [Warning] For categorical features, max_bin and max_bin_by_feature may be ignored with a large number of categories. [LightGBM] [Info] Number of positive: 89852, number of negative: 332212 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.030787 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 27240 [LightGBM] [Info] Number of data points in the train set: 422064, number of used features: 18 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.212887 -> initscore=-1.307609 [LightGBM] [Info] Start training from score -1.307609 Training until validation scores don't improve for 500 rounds [100] training's auc: 0.82001 valid_1's auc: 0.82123 [200] training's auc: 0.82421 valid_1's auc: 0.821281 [300] training's auc: 0.829333 valid_1's auc: 0.820999 [400] training's auc: 0.83413 valid_1's auc: 0.820356 [500] training's auc: 0.837975 valid_1's auc: 0.819708 [600] training's auc: 0.841115 valid_1's auc: 0.819106 Early stopping, best iteration is: [174] training's auc: 0.823088 valid_1's auc: 0.821376 finish! 2023下期
5.モデルの性能確認¶
作成したモデルの性能の確認。確認項目を以下とする。
また、最も予測角度の高いものにベットすることとする。
-
- 単勝回収率と単勝的中率
-
- 特徴量重要度
-
- オッズに対する勝率と支持率の関係グラフ
- 馬場別
- レース場別
- SMILE別
- 全体
5-1.単勝回収率と単勝的中率¶
summary_list = []
for target_year in dataset_mapping.keys():
dftrain, dfvalid, dftest = dataset_mapping[target_year].values()
insert_data = {
"year": target_year,
}
for key, dfval in dataset_mapping[target_year].items():
dfbet = dfval[dfval["pred"].isin([1])]
dfreturn = dfbet[dfbet["label"].isin([1])]
insert_data["rtn_rate_"+key] = dfreturn["odds"].sum()/len(dfbet)
insert_data["hit_rate_"+key] = len(dfreturn)/len(dfbet)
summary_list += [insert_data.copy()]
dfsummary = pd.DataFrame(summary_list)[["year"]+["rtn_rate_"+key for key in ["train", "valid", "test"]] + ["hit_rate_"+key for key in ["train", "valid", "test"]]]
dfsummary
| year | rtn_rate_train | rtn_rate_valid | rtn_rate_test | hit_rate_train | hit_rate_valid | hit_rate_test | |
|---|---|---|---|---|---|---|---|
| 0 | 2018上期 | 0.807756 | 0.814311 | 0.727845 | 0.324648 | 0.342522 | 0.300242 |
| 1 | 2018下期 | 0.802993 | 0.722881 | 0.784299 | 0.326113 | 0.299031 | 0.340896 |
| 2 | 2019上期 | 0.810082 | 0.781134 | 0.760309 | 0.325997 | 0.340896 | 0.311349 |
| 3 | 2019下期 | 0.801107 | 0.755734 | 0.819475 | 0.326175 | 0.310755 | 0.341270 |
| 4 | 2020上期 | 0.799049 | 0.812698 | 0.790064 | 0.325358 | 0.340049 | 0.324956 |
| 5 | 2020下期 | 0.792895 | 0.795032 | 0.757435 | 0.324258 | 0.326125 | 0.307931 |
| 6 | 2021上期 | 0.816638 | 0.757993 | 0.762433 | 0.328885 | 0.307931 | 0.312166 |
| 7 | 2021下期 | 0.830465 | 0.749733 | 0.798842 | 0.330397 | 0.308605 | 0.330896 |
| 8 | 2022上期 | 0.809514 | 0.818464 | 0.817548 | 0.326922 | 0.335771 | 0.341346 |
| 9 | 2022下期 | 0.817184 | 0.828185 | 0.830072 | 0.328107 | 0.343750 | 0.340936 |
| 10 | 2023上期 | 0.810209 | 0.850900 | 0.785216 | 0.327860 | 0.346339 | 0.329928 |
| 11 | 2023下期 | 0.809885 | 0.787380 | 0.780469 | 0.328655 | 0.329928 | 0.325721 |
結果から、的中率は通年して3割程度に対して、回収率が80%前後であることから、
一番人気ばかりに投票している可能性が高く想定通りの結果と言える
# 各人気のベット率を確認
summary_list = []
for target_year in dataset_mapping.keys():
dftrain, dfvalid, dftest = dataset_mapping[target_year].values()
insert_data = {
"year": target_year,
}
for key, dfval in dataset_mapping[target_year].items():
dfbet = dfval[dfval["pred"].isin([1])]
insert_data |= dfbet["favorite"].value_counts().to_dict()
summary_list += [insert_data.copy()]
dfsummary = pd.DataFrame(summary_list)
display(dfsummary[["year"]+sorted(dfsummary.columns.tolist()[1:])].rename(columns={
fav: f"{fav}人気"
for fav in dfsummary.columns.tolist()[1:]
}).fillna(""))
| year | 1人気 | 2人気 | 3人気 | 4人気 | 5人気 | 6人気 | 7人気 | 8人気 | 9人気 | 10人気 | 11人気 | 12人気 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018上期 | 1542 | 93 | 12 | 5 | ||||||||
| 1 | 2018下期 | 1611 | 52 | 10 | 2 | 1.0 | 1.0 | ||||||
| 2 | 2019上期 | 1567 | 89 | 25 | 2 | 1.0 | 2.0 | ||||||
| 3 | 2019下期 | 1518 | 104 | 14 | 2 | 2.0 | |||||||
| 4 | 2020上期 | 1571 | 119 | 21 | 2 | 2.0 | |||||||
| 5 | 2020下期 | 1401 | 198 | 15 | 11 | 5.0 | |||||||
| 6 | 2021上期 | 1528 | 135 | 19 | 1 | 2.0 | 10.0 | 4.0 | 1.0 | ||||
| 7 | 2021下期 | 1441 | 181 | 15 | 4 | 3.0 | 20.0 | 9.0 | 4.0 | 3.0 | 1.0 | 1.0 | 1.0 |
| 8 | 2022上期 | 1484 | 159 | 21 | 41 | 18.0 | 5.0 | 3.0 | |||||
| 9 | 2022下期 | 1481 | 161 | 22 | 1 | 1.0 | 14.0 | 5.0 | 2.0 | 1.0 | |||
| 10 | 2023上期 | 1455 | 195 | 12 | 2 | 15.0 | 3.0 | 1.0 | |||||
| 11 | 2023下期 | 1484 | 165 | 13 | 2 | 19.0 | 8.0 | 3.0 |
ほとんど1番人気にしか賭けていないことが分かる。オッズを特徴量に入れた場合の影響の強さが非常によく出ている。
5-2.特徴量重要度を確認する¶
maxrow = len(dataset_mapping)//2
fig, axes = plt.subplots(maxrow, 2, figsize=(18, 6*maxrow))
for num, (key, dfval) in enumerate(dfimp_dict.items()):
ncol = num % 2
nrow = (num//2) % maxrow
axes[nrow, ncol].barh(dfval["gain"].index, dfval["gain"], label=key)
axes[nrow, ncol].grid(ls=":")
axes[nrow, ncol].set_title(f"year: {key}")
plt.show()

# 実際の値も見たい
dfall_list = []
for key, dfval in dfimp_dict.items():
dfval[key] = dfval["gain"]
dfall_list += [dfval[key].apply(lambda d: d if d>0 else None)]
print("重要度0のものは非表示")
dfimp = pd.concat(dfall_list, axis=1)
display(dfimp.loc[dfimp.mean(axis=1).sort_values(ascending=False).index].fillna(""))
重要度0のものは非表示
| 2018上期 | 2018下期 | 2019上期 | 2019下期 | 2020上期 | 2020下期 | 2021上期 | 2021下期 | 2022上期 | 2022下期 | 2023上期 | 2023下期 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| odds | 1493413.088041 | 1406990.7551 | 2147410.152729 | 2153913.272053 | 2501991.257439 | 1876843.679409 | 3304931.261246 | 3653589.113205 | 3765026.820545 | 4091893.807575 | 4200428.681904 | 4531159.385696 |
| teacherId_en | 58530.902954 | 40922.5264 | 78505.104551 | 61833.676544 | 64259.356224 | 33838.083923 | 90500.55817 | 103623.478939 | 88628.976841 | 97604.333328 | 85524.76408 | 91365.145889 |
| horseId_en | 7731.41761 | 1369.298992 | 33131.372139 | 17172.102749 | 26028.917847 | 2934.555103 | 99847.591366 | 233284.870705 | 93809.037773 | 153601.448128 | 76427.258656 | 94317.165348 |
| favorite | 30513.460831 | 2892.067982 | 54654.903694 | 75752.255188 | 46286.444687 | 2132.899399 | 55006.143318 | 73058.536507 | 60390.29538 | 93396.942867 | 62328.186512 | 56135.80389 |
| jockeyId_en | 26420.8097 | 15605.260077 | 33643.563557 | 24575.462187 | 26719.364681 | 11007.395817 | 38694.525166 | 44249.030975 | 35355.879646 | 41383.710243 | 35160.640999 | 36560.162701 |
| age | 117.040901 | 74.364201 | 280.666901 | 2114.723392 | 4180.957115 | 2210.943108 | 4031.277699 | 2581.706604 | 3652.393372 | |||
| race_span | 1141.148598 | 341.849705 | 470.105206 | 190.993698 | 202.167702 | |||||||
| place_en | ||||||||||||
| dist_cat_en | ||||||||||||
| condition_en | ||||||||||||
| sex_en | ||||||||||||
| field_en | ||||||||||||
| distance | ||||||||||||
| number | ||||||||||||
| gl | ||||||||||||
| weight | ||||||||||||
| jweight | ||||||||||||
| boxNum |
当然ながら、重要度に関してもオッズの項目がずば抜けて高い。しかし、競走馬、調教師や騎手による影響も比較的高いという結果に興味深さがある。
なぜなら、オッズというのは、レース状況や出走馬たちの能力および調教師や騎手の技量、そのすべてのファクターが含まれている。いわば、経済学でいうところの効率的市場仮説に似た性質であると自分は捉えている。
そのため、その仮説が厳密に真であるならば、上記で得られる特徴量重要度の結果というのは、オッズ以外の項目がすべて0(もしくはそれに近しい値)になっていても可笑しくないと考える。
しかしながら、結果で見ると騎手、調教師や競走馬の要素は、オッズに対して2桁程度の差しかない。
つまり、これは着順の決まり方というのはオッズの項目以外による影響が少なからず存在している。
要は、市場が考慮できていないファクターが存在している可能性があると考える。
悲観的な見方をすれば、まだ考慮しきれていない項目が存在している可能性もある。
5-3.オッズに対する勝率と支持率の関係グラフ¶
q1, q2, q3 = 3, 40, 150
def odds_round_func(d):
if d < 200:
# if d < 2:
# return d
# if d < q1:
# d+=0.5
# return int(d) + int(d-int(d) > 0.5)*0.5
return round(d, 1-sum([d>=q1, d>=q2, d>=q3]))
else:
return 200
def calc_winrate_by_odds_all(dataset_mapping, column: str=None, query: list=None):
summary_all_dict = {}
cumurative_df_list = {"valid":[], "test":[]}
for key, df_dict in dataset_mapping.items():
if column is None:
dftrain, dfva, dfte = [df_dict[col] for col in ["train", "valid", "test"]]
else:
if isinstance(query, list):
dftrain, dfva, dfte = [df_dict[col][df_dict[col][column].isin(query)] for col in ["train", "valid", "test"]]
else:
raise Exception(f"query must be list type. query: {query}")
cumurative_df_list["valid"] += [dfva]
cumurative_df_list["test"] += [dfte]
dfvalid = pd.concat(cumurative_df_list["valid"])
dftest = pd.concat(cumurative_df_list["test"])
summary_all_dict[key] = calc_winrate_by_odds(dftrain, dfvalid, dftest)
del cumurative_df_list
return summary_all_dict
# 関数を用意
def calc_winrate_by_odds(dftrain: pd.DataFrame, dfvalid: pd.DataFrame, dftest: pd.DataFrame) -> dict[str, pd.DataFrame]:
summary_dict = {}
for key, idf in zip(["train", "valid", "test"], [dftrain, dfvalid, dftest]):
idfbet = idf[idf["pred"].isin([1])]
idfbet["odds_round"] = idfbet["odds"].map(odds_round_func)
idfcount: pd.DataFrame = pd.concat(
[
pd.DataFrame(idfbet["odds_round"].value_counts().sort_index()).rename(columns={"count": "all"}),
pd.DataFrame(idfbet[idfbet["label"].isin([1])]["odds_round"].value_counts().sort_index()).rename(columns={"count": "label1"})
],
axis=1
)
idfcount["勝率"] = idfcount["label1"]/idfcount["all"]
idfcount["支持率"] = 0.8/idfcount.index
idfcount["回収率100%超"] = 1/idfcount.index
summary_dict[key] = idfcount[["勝率", "支持率", "回収率100%超"]].fillna(-0.01)
return summary_dict
def plot_summary(summary_dict: dict[str, pd.DataFrame], title: str):
max_idx = max([dfval.index.max() for dfval in summary_dict.values()])
max_columns = sum([max_idx>1, max_idx>q1, max_idx>q2])
fig, axes = plt.subplots(3, max_columns, figsize=(8*max_columns, 4*max(2, max_columns)))
for num, (key, dfval) in enumerate(summary_dict.items()):
for idx, idfval in enumerate([dfval.loc[:q1], dfval[q1:q2], dfval[q2:]][:max_columns]):
if max_columns > 1:
ax = axes[num, idx]
else:
ax = axes[num]
for col in ["勝率", "支持率", "回収率100%超"]:
if col == "勝率":
idfval[col].plot(ax=ax)
idfval.reset_index(names="odds_round").plot(ax=ax, kind="scatter", x="odds_round", y=col)
else:
idfval[col].plot(ax=ax)
ax.legend(loc="best")
ax.grid(ls=":")
ax.set_ylabel(key)
ax.set_yticks(np.arange(0.1, 1.1, 0.1))
ax.set_xticks(idfval[col].index.tolist())
ax.set_xticklabels(idfval[col].index.tolist(), rotation=60)
fig.suptitle(title, fontweight="bold")
fig.tight_layout()
plt.show()
全体の結果¶
min_key = min(dataset_mapping.keys())
# summary_dict = calc_winrate_by_odds(dftrain, dfvalid, dftest)
summary_all_dict = calc_winrate_by_odds_all(dataset_mapping)
max_key = max(dataset_mapping.keys())
plot_summary(summary_all_dict[max_key], f"全体\n集計範囲: {min_key} - {max_key}")

全体の傾向を見ると、学習データでさえも、オッズの低い範囲(大体オッズ1~5あたり)では、的中率が支持率に沿っていることがわかり、これはオッズがこの値になっている場合に対して、必ず賭けている状態であると考えられる。
これは、検証データおよびテストデータでも同じ傾向であることから、オッズが低いものを中心に賭けている。
しかし、オッズが比較的高めのオッズ6以降でみると、学習時点で回収率100%超(緑線)を超えているにも関わらず、検証データとテストデータではその傾向がほとんど見られないため、オッズ6以降ではモデルの予測性能は信頼できないことがわかる。
馬場別の結果¶
summary_field_dict = {}
summary_field_all_dict = {}
for field in ["芝", "ダ"]:
max_key = max(dataset_mapping.keys())
summary_field_all_dict[field] = calc_winrate_by_odds_all(dataset_mapping, "field", [field])
plot_summary(summary_field_all_dict[field][max_key], f"field: {field}\n集計範囲: {min_key} - {max_key}")


SMILE別の結果¶
summary_dist_cat_dict = {}
summary_dist_cat_all_dict = {}
for dist_cat in df.sort_values("dist_cat_en")["dist_cat"].unique():
max_key = max(dataset_mapping.keys())
summary_dist_cat_all_dict[dist_cat] = calc_winrate_by_odds_all(dataset_mapping, "dist_cat", [dist_cat])
plot_summary(summary_dist_cat_all_dict[dist_cat][max_key], f"dist_cat: {dist_cat}\n集計範囲: {min_key} - {max_key}")





レース場別の結果¶
summary_place_dict = {}
summary_place_all_dict = {}
for place in df.sort_values("place_en")["place"].unique():
max_key = max(dataset_mapping.keys())
summary_place_all_dict[place] = calc_winrate_by_odds_all(dataset_mapping, "place", [place])
plot_summary(summary_place_all_dict[place][max_key], f"place: {place}\n集計範囲: {min_key} - {max_key}")










回収率の確認¶
確認する意味はないのだが、気になる人だけここは参考程度にみてください。
def filter_cond(idf, quantile):
dffilter = idf["pred"].isin([1])
return dffilter
quantile_map = {
year: dfdict["train"][dfdict["train"]["label"].isin([1])]["pred_prob"].quantile(0.0)
for year, dfdict in dataset_mapping.items()
}
return_summary_list = []
bet_list = []
for mode in ["train", "valid", "test"]:
print(f"対象: {mode}")
for year in dataset_mapping.keys():
idf = dataset_mapping[year][mode]
insert_data = {
"mode": mode
}
dffilter = filter_cond(idf, quantile_map[year])
idfb = idf[dffilter]
idfb["mode"] = mode
idfb["year"] = year
bet_list += [idfb.copy()]
profit = idfb[idfb["label"].isin([1])]["odds"].sum()
if len(idfb) == 0:
continue
print(
f"年次: {year},\t",
f'収益: {profit.round(3)},\t',
f'回収率: {round(profit/len(idfb), 3)},\t',
f'的中数: {sum(idfb["label"].isin([1]))},\t',
f'的中率: {round(sum(idfb["label"].isin([1]))/len(idfb), 3)},\t',
f'bet数: {len(idfb)},\t'
f'bet率: {round(len(idfb)/dataset_mapping[year][mode]["raceId"].nunique(), 4)}'
)
insert_data |= {
"year": year,
"profit": profit,
"prate": profit/len(idfb),
"hit": sum(idfb["label"].isin([1])),
"hitRate": sum(idfb["label"].isin([1]))/len(idfb),
"bet": len(idfb),
"betRate": len(idfb)/dataset_mapping[year][mode]["raceId"].nunique()
}
return_summary_list += [insert_data]
print("")
dfreturn = pd.DataFrame(return_summary_list)
dfgroup = dfreturn.groupby("mode")
for key in ["train", "valid", "test"]:
dfmode = dfgroup.get_group(key)
print(key, dfmode["profit"].sum()/dfmode["bet"].sum())
dfbet = pd.concat(bet_list).reset_index(drop=True)
対象: train 年次: 2018上期, 収益: 9362.7, 回収率: 0.808, 的中数: 3763, 的中率: 0.325, bet数: 11591, bet率: 1.0 年次: 2018下期, 収益: 10676.6, 回収率: 0.803, 的中数: 4336, 的中率: 0.326, bet数: 13296, bet率: 1.0 年次: 2019上期, 収益: 12109.1, 回収率: 0.81, 的中数: 4873, 的中率: 0.326, bet数: 14948, bet率: 1.0 年次: 2019下期, 収益: 13316.8, 回収率: 0.801, 的中数: 5422, 的中率: 0.326, bet数: 16623, bet率: 1.0 年次: 2020上期, 収益: 14627.4, 回収率: 0.799, 的中数: 5956, 的中率: 0.325, bet数: 18306, bet率: 1.0 年次: 2020下期, 収益: 15813.5, 回収率: 0.793, 的中数: 6467, 的中率: 0.324, bet数: 19944, bet率: 1.0 年次: 2021上期, 収益: 17684.3, 回収率: 0.817, 的中数: 7122, 的中率: 0.329, bet数: 21655, bet率: 1.0 年次: 2021下期, 収益: 19324.1, 回収率: 0.83, 的中数: 7688, 的中率: 0.33, bet数: 23269, bet率: 1.0 年次: 2022上期, 収益: 20200.6, 回収率: 0.81, 的中数: 8158, 的中率: 0.327, bet数: 24954, bet率: 1.0 年次: 2022下期, 収益: 21733.0, 回収率: 0.817, 的中数: 8726, 的中率: 0.328, bet数: 26595, bet率: 1.0 年次: 2023上期, 収益: 22895.7, 回収率: 0.81, 的中数: 9265, 的中率: 0.328, bet数: 28259, bet率: 1.0 年次: 2023下期, 収益: 24235.8, 回収率: 0.81, 的中数: 9835, 的中率: 0.329, bet数: 29925, bet率: 1.0 対象: valid 年次: 2018上期, 収益: 1388.4, 回収率: 0.814, 的中数: 584, 的中率: 0.343, bet数: 1705, bet率: 1.0 年次: 2018下期, 収益: 1194.2, 回収率: 0.723, 的中数: 494, 的中率: 0.299, bet数: 1652, bet率: 1.0 年次: 2019上期, 収益: 1308.4, 回収率: 0.781, 的中数: 571, 的中率: 0.341, bet数: 1675, bet率: 1.0 年次: 2019下期, 収益: 1271.9, 回収率: 0.756, 的中数: 523, 的中率: 0.311, bet数: 1683, bet率: 1.0 年次: 2020上期, 収益: 1331.2, 回収率: 0.813, 的中数: 557, 的中率: 0.34, bet数: 1638, bet率: 1.0 年次: 2020下期, 収益: 1360.3, 回収率: 0.795, 的中数: 558, 的中率: 0.326, bet数: 1711, bet率: 1.0 年次: 2021上期, 収益: 1223.4, 回収率: 0.758, 的中数: 497, 的中率: 0.308, bet数: 1614, bet率: 1.0 年次: 2021下期, 収益: 1263.3, 回収率: 0.75, 的中数: 520, 的中率: 0.309, bet数: 1685, bet率: 1.0 年次: 2022上期, 収益: 1343.1, 回収率: 0.818, 的中数: 551, 的中率: 0.336, bet数: 1641, bet率: 1.0 年次: 2022下期, 収益: 1378.1, 回収率: 0.828, 的中数: 572, 的中率: 0.344, bet数: 1664, bet率: 1.0 年次: 2023上期, 収益: 1417.6, 回収率: 0.851, 的中数: 577, 的中率: 0.346, bet数: 1666, bet率: 1.0 年次: 2023下期, 収益: 1310.2, 回収率: 0.787, 的中数: 549, 的中率: 0.33, bet数: 1664, bet率: 1.0 対象: test 年次: 2018上期, 収益: 1202.4, 回収率: 0.728, 的中数: 496, 的中率: 0.3, bet数: 1652, bet率: 1.0 年次: 2018下期, 収益: 1313.7, 回収率: 0.784, 的中数: 571, 的中率: 0.341, bet数: 1675, bet率: 1.0 年次: 2019上期, 収益: 1279.6, 回収率: 0.76, 的中数: 524, 的中率: 0.311, bet数: 1683, bet率: 1.0 年次: 2019下期, 収益: 1342.3, 回収率: 0.819, 的中数: 559, 的中率: 0.341, bet数: 1638, bet率: 1.0 年次: 2020上期, 収益: 1351.8, 回収率: 0.79, 的中数: 556, 的中率: 0.325, bet数: 1711, bet率: 1.0 年次: 2020下期, 収益: 1222.5, 回収率: 0.757, 的中数: 497, 的中率: 0.308, bet数: 1614, bet率: 1.0 年次: 2021上期, 収益: 1284.7, 回収率: 0.762, 的中数: 526, 的中率: 0.312, bet数: 1685, bet率: 1.0 年次: 2021下期, 収益: 1310.9, 回収率: 0.799, 的中数: 543, 的中率: 0.331, bet数: 1641, bet率: 1.0 年次: 2022上期, 収益: 1360.4, 回収率: 0.818, 的中数: 568, 的中率: 0.341, bet数: 1664, bet率: 1.0 年次: 2022下期, 収益: 1382.9, 回収率: 0.83, 的中数: 568, 的中率: 0.341, bet数: 1666, bet率: 1.0 年次: 2023上期, 収益: 1306.6, 回収率: 0.785, 的中数: 549, 的中率: 0.33, bet数: 1664, bet率: 1.0 年次: 2023下期, 収益: 1298.7, 回収率: 0.78, 的中数: 542, 的中率: 0.326, bet数: 1664, bet率: 1.0 train 0.8099757383754737 valid 0.7895839583958397 test 0.784511700155334


コメント