
【チュートリアル #2】深層学習を使った競馬予想AI作成¶
0-1.本講座の目的¶
深層学習を使った競馬予想AIの作成方法を本講座で解説していきます。
本講座を通して、PyTorchを使った競馬予想AIの深層学習モデルを自力で作れるようになることを目的としています。
まずは、深層学習の基本をおさえるため、
本Notebookでは、PyTorchを使った深層学習モデル作成をするためのデータセット作成のチュートリアルです。
本チュートリアルで扱う項目は以下
- 深層学習の基本的な知識
- 深層学習の学習過程
- データセット作成:今回の内容
- PyTorchのモデル構築方法
- 学習・推論の実行
- モデルの解釈方法
- モデル保存
前回の内容はこちら

0-2.前提環境¶
使用する深層学習ライブラリの紹介です。
- Python 3.10.5
- PyTorch 2.3.1
- GPU使う場合は:CUDA 18
ない場合はpip等でインストールしてください。
0-3.宣伝(環境準備)¶
本講座で扱うソースでは一部秘匿させていただいております。
ソースは「ゼロから作る競馬予想モデル・機械学習入門」にあるものを使用しています。
また、本Notebookは「dev-um-ai > notebook > DeepLearning > 0000-2_deeplearning_tutrial2.ipynb」にあります。
環境構築(パッケージ管理)はpoetryを使用しているので、プロジェクトファイルさえあればコマンド一発で環境構築が完了するので、ぜひご活用ください。
Bookersアカウントとご自身のYouTubeアカウントを連携していただき、以下のチャンネルを登録して頂きますと1000円引きで入手出来ますのでぜひ登録よろしくお願いいたします。

1.データセット作成¶
データセットの作成に必要な前処理は以下である
- 欠損値補完
- データの標準化
- カテゴリのエンコード
1-0.まずはデータ前処理¶
LightGBMベースのモデルでも深層学習ベースのモデルでも共通の前処理を行う。
ベースの前処理については以下の記事を参照

一部のソースは「ゼロから作る競馬予想モデル・機械学習入門」にあるものを使っていますので、ご注意ください。
import pathlib
import warnings
import sys
sys.path.append(".")
sys.path.append("../..")
from src.core.meta.bet_name_meta import BetName # noqa
from src.data_manager.preprocess_tools import DataPreProcessor # noqa
from src.data_manager.data_loader import DataLoader # noqa
warnings.filterwarnings("ignore")
root_dir = pathlib.Path(".").absolute().parent.parent
dbpath = root_dir / "data" / "keibadata.db"
start_year = 2000 # DBが持つ最古の年を指定
split_year = 2014 # 学習対象期間の開始年を指定
target_year = 2019 # テスト対象期間の開始年を指定
end_year = 2023 # テスト対象期間の終了年を指定 (当然DBに対象年のデータがあること)
# 各種インスタンスの作成
data_loader = DataLoader(
start_year,
end_year,
dbpath=dbpath # dbpathは各種環境に合わせてパスを指定してください。絶対パス推奨
)
dataPreP = DataPreProcessor(
# キャッシュ機能を使用する場合にTrueを指定。デフォルト:True
use_cache=True,
cache_dir=pathlib.Path("./data")
)
df = data_loader.load_racedata()
dfblood = data_loader.load_horseblood()
df = dataPreP.exec_pipeline(
df,
dfblood,
blood_set=["s", "b", "bs", "bbs", "ss", "sss", "ssss", "bbbs"],
lagN=5
)
1-1.欠損値の確認¶
深層学習に限らず、基本的な機械学習モデルは入力するデータに欠損値が存在してはいけない。
LightGBMは欠損値があってもお構いなく入力データと出来たので気にしてなかったが、今回からは真面目に取り組む
まずはセカンドモデルの再現をしたいので、セカンドモデルで使っていた特徴量を用意する
ここで作成するdataset_mappingは、2019年から2023年のデータを6分割したものをテストデータとしているデータセット群になります。
つまり、以下のような辞書型のデータです。
dataset_mapping = {
"2019first": {
"train": "2014年1月1日 ~ 2018年6月30日まで",
"valid": "2018年7月1日 ~ 2018年12月31日まで",
"test": "2019年1月1日 ~ 2019年6月30日まで"
},
"2019second": {
"train": "2014年1月1日 ~ 2018年12月31日まで",
"valid": "2019年1月1日 ~ 2019年6月30日まで",
"test": "2019年7月1日 ~ 2019年12月31日まで"
},
# ・・・
"2023first": {
"train": "2014年1月1日 ~ 2022年6月30日まで",
"valid": "2022年7月1日 ~ 2022年12月31日まで",
"test": "2023年1月1日 ~ 2023年6月30日まで"
},
"2023second": {
"train": "2014年1月1日 ~ 2022年12月31日まで",
"valid": "2023年1月1日 ~ 2023年6月30日まで",
"test": "2023年7月1日 ~ 2023年12月31日まで"
},
}
from src.data_manager.dataset_tools import DatasetGenerator
dataset_generator = DatasetGenerator(split_year, target_year, end_year)
target_category = [["stallionId"], ["breedId"],
["bStallionId"], ["b2StallionId"]]
target_sub_category = ["field", "dist_cat"]
cat_list = ["field", "place", "dist_cat",
"condition", "inoutside", "direction", "horseId", 'weather',]
for cat in cat_list:
df[cat] = df[cat].astype("category")
dataset_mapping = dataset_generator.make_dataset_mapping(df)
dataset_generator.calcurate_category_winrate(
df, dataset_mapping, target_category, target_sub_category, [1])
# セカンドモデルの特徴量
feature_columns = [
'distance',
'number',
'boxNum',
'odds',
'favorite',
'age',
'jweight',
'weight',
'gl',
'race_span',
"raceGrade",
] + dataPreP.encoding_columns + [
"stallionId", "breedId", "bStallionId", "b2StallionId"
] + ['winR_stallion', 'winR_breed', 'winR_bStallion', 'winR_b2Stallion']
欠損値の確認は、DataFrameのisnaメソッドとsumメソッドで確認できる
import pandas as pd
alllist = []
for key, dataset in dataset_mapping.items():
dflist = []
for mode in ["train", "valid", "test"]:
idf = dataset.__dict__[
mode][feature_columns].isna().sum(axis=0).rename(mode)
dflist += [idf[idf > 0]]
alllist += [pd.concat(dflist,
axis=1).rename(columns=lambda x: f"{key}_{x}").T]
display(pd.concat(alllist))
どのデータセットも欠損値があるのはrace_spanのカラムだけだった。
race_spanが欠損値というのは、初出走など前回の出走情報がない場合なので、ここは簡単に馬齢×365とすれば良いと考える。
for dataset in dataset_mapping.values():
for mode in ["train", "valid", "test"]:
idf = dataset.__dict__[mode]
idf["race_span_fill"] = idf[["age", "race_span"]].apply(lambda row: int(
row["age"])*365 if pd.isna(row["race_span"]) else row["race_span"], axis=1)
dataset.__dict__[mode] = idf.copy()
欠損値がなくなったことを確認
feature_columns += ["race_span_fill"]
feature_columns.remove("race_span")
alllist = []
for key, dataset in dataset_mapping.items():
dflist = []
for mode in ["train", "valid", "test"]:
idf = dataset.__dict__[
mode][feature_columns].isna().sum(axis=0).rename(mode)
dflist += [idf[idf > 0]]
alllist += [pd.concat(dflist,
axis=1).rename(columns=lambda x: f"{key}_{x}").T]
display(pd.concat(alllist))
またこの欠損値補完の影響で、データにかなりの偏りが出来たと考える
dataset.train["race_span_fill"].describe()
結果から中央値が36であるにも関わらず平均が132となっているため、データ上ではレースの出走間隔が平均して132日間隔であると判断されてしまい、実態にそぐわない。
なので、欠損値補完をする前の平均値と標準偏差を使って標準化するようにすることに注意
# 念のため欠損値補完前の分布を確認
display(df["race_span"].describe().to_frame(name="補完前").T)
欠損値補完前では、中央値が28日で平均値が51日なので、まあ良しとします。
1-2.データの標準化
データの標準化とは、対象のデータからその平均を引き、標準偏差で除算して、データを平均が0で標準偏差1にスケーリングすることです。
深層学習などの数値を入力として取るような機械学習モデルでは、受け取るデータは全て同じスケールである必要があります。
スケールの違うデータを比較可能にすることや学習の安定化など標準化の利点は様々あり、決定木モデル以外では必ず実施しなければならない前処理です。
先ほど作成したdataset_mappingは、各期間に対する学習・検証・テストの3つのデータがまとめて入っています。
なので、データの標準化をする際には、平均と標準偏差の計算を以下の組み合わせで行うと良いと思います。
【標準化の組合せ例】
- 学習データ:学習データの平均と標準偏差
- 検証データ:学習データの平均と標準偏差
- テストデータ:学習+検証データの平均と標準偏差
処理ステップ
- 量的変数の特徴量の確認:ここでカテゴリ特徴量(質的変数)もリストアップしておく
- 量的変数の特徴量の精査:標準化の方針決め
- 標準化の実行
1-2-1.量的変数の特徴量の確認¶
dftype = dataset.train[feature_columns].dtypes.to_frame("TypeInfo")
dftype["TypeName"] = dftype["TypeInfo"].apply(lambda x: x.name)
category_list = dftype[dftype["TypeName"].isin(["category"])].index.tolist()
numerous_list = dftype[~dftype["TypeName"].isin(["category"])].index.tolist()
numerous_list
1-2-2.量的変数の特徴量の精査¶
競馬の文脈で見た場合、量的変数の扱いとしては2パターンあると考える
- レース全体で意味のあるデータ:distance, age, race_span_fill
- レースごとに意味のあるデータ:number, boxNum, odds, favorite, jweight, weight, gl, winR_…
よって、標準化のプロセスとしても、レース全体のデータで標準化するパターンとレースごとに標準化するパターンの2通りになると考える。
この場合、標準化としてレース全体の場合は【標準化の組合せ例】で挙げた組み合わせで標準化すべきで、後者のレースごとの場合はテストデータでも検証データでも関係なくレースごとの標準化をした方が良いと考える。
出走間隔:race_span_fillの扱いについては、先でも言及した通り標準化の平均値と標準偏差は補完前のrace_spanによる結果を用いることとする。
また、勝率関連の情報であるwinR_…の特徴量については、勝率としての値が重要であることから標準化の対象から外すこととする。
さらに、馬体重増減であるglの特徴量については、元の馬体重であるweightを基準にした値であるので、割合として計算し直したものを使用することとし、標準化の対象から除外する
# よって、標準化する特徴量をまとめる
# レース全体で標準化する特徴量
sd_by_all_race = ["distance", "age"]
# レースごとに標準化する特徴量
sd_by_a_race = ["number", "boxNum", "odds", "favorite", "jweight", "weight"]
1-2-3.標準化の実行
精査の結果から、標準化を実行
for key, dataset in dataset_mapping.items():
for sd_col in sd_by_all_race + ["race_span_fill"]:
sdcol = sd_col.split("_fill")[0]
idf = pd.concat([dataset.train[sdcol], dataset.valid[sdcol]])
mean_train = dataset.train[sdcol].mean()
mean_tr_va = idf.mean()
std_train = dataset.train[sdcol].std()
std_tr_va = idf.std()
dataset.train[sd_col +
"_dev"] = (dataset.train[sd_col]-mean_train)/std_train
dataset.valid[sd_col +
"_dev"] = (dataset.valid[sd_col]-mean_train)/std_train
dataset.test[sd_col +
"_dev"] = (dataset.test[sd_col]-mean_tr_va)/std_tr_va
for mode in ["train", "valid", "test"]:
dataset.__dict__[mode]["gl"+"_dev"] = (dataset.__dict__[
mode]["weight"]+dataset.__dict__[mode]["gl"])/dataset.__dict__[mode]["weight"]
for sdcol in sd_by_a_race:
for mode in ["train", "valid", "test"]:
mean_dict = dataset.__dict__[mode][["raceId", sdcol]].groupby("raceId")[
sdcol].mean()
std_dict = dataset.__dict__[mode][["raceId", sdcol]].groupby("raceId")[
sdcol].std()
dataset.__dict__[mode][sdcol+"_dev"] = (dataset.__dict__[mode][sdcol] - dataset.__dict__[
mode]["raceId"].map(mean_dict))/dataset.__dict__[mode]["raceId"].map(std_dict)
# 標準偏差が0になるパターンもあり得るので、その場合は全て0とする
dataset.__dict__[mode][sdcol+"_dev"].fillna(0, inplace=True)
標準化されているか確認
dataset.train[[n+"_dev" for n in numerous_list[:-5] +
numerous_list[-1:]] + numerous_list[-5:-1]]
上手くいってそうである
1-3.カテゴリのエンコード¶
カテゴリのエンコードは、機械学習モデルが扱いやすいようにカテゴリ変数(文字列やカテゴリ名)を数値に変換するプロセスです。
カテゴリ変数を適切にエンコードすることで、モデルがより正確な予測を行えるようになります。
ここでは、エンコードの基本的な手法を紹介し、今回の競馬AIではどういったエンコードをした方が良いかを考える。
1-3-1.基本的なエンコード手法¶
ここでは、主なエンコード手法とそれぞれの特徴について詳しく説明します。
1. ラベルエンコーディング (Label Encoding)¶
- 方法: 各カテゴリに整数ラベルを割り当てるシンプルな方法です。たとえば、
{"赤": 0, "青": 1, "緑": 2}のように、カテゴリ変数を整数に置き換えます。 - 利点: 単純で実装が容易です。カテゴリ数が多くない場合に適しています。
- 欠点: カテゴリに順序がない場合でも、整数に変換すると、モデルが暗黙的な「順序関係」を持つとみなしてしまう可能性があります。線形モデルでは、この関係が誤った推定につながる可能性があるため、順序を持たないカテゴリには向きません。
2. ワンホットエンコーディング (One-Hot Encoding)¶
- 方法: 各カテゴリをバイナリの列に展開する方法です。たとえば、3つのカテゴリ
{"赤", "青", "緑"}では、「赤」なら[1, 0, 0], 「青」なら[0, 1, 0], 「緑」なら[0, 0, 1]となります。 - 利点: 各カテゴリが独立してエンコードされるため、カテゴリ間に順序の関係があるとは解釈されません。また、線形モデルでも順序性を誤解せずに扱えるため、順序がないカテゴリに適しています。
- 欠点: カテゴリ数が増えると次元数も増加し、データのサイズが大きくなりがちです(特にカテゴリ数が多い場合)。「次元の呪い」に陥りやすく、計算コストが上がることが問題です。
3. ターゲットエンコーディング (Target Encoding)¶
- 方法: カテゴリごとに目的変数(ターゲット)と関連する平均値などを用いてエンコードします。例えば、
{A, B, C}のカテゴリ変数に対し、カテゴリAのターゲットの平均値が0.5、カテゴリBが0.7、カテゴリCが0.2である場合、それぞれにこれらの値を割り当てます。 - 利点: 高次元カテゴリでもエンコードがシンプルに済み、メモリ効率が良いです。また、ターゲット変数との関連性を利用するため、モデルの予測精度を向上させる可能性が高いです。
- 欠点: 過学習のリスクがあり、特にカテゴリ数が少ない場合やターゲットがノイズを含む場合には、精度が落ちる可能性もあります。対策として、クロスバリデーションやスムージングが推奨されます。
4. 頻度エンコーディング (Frequency Encoding)¶
- 方法: 各カテゴリの出現頻度をエンコードに使用します。たとえば、カテゴリ
Aが全データの30%、カテゴリBが50%の場合、Aには0.3、Bには0.5を割り当てます。 - 利点: カテゴリの情報を保存しつつ次元数を増やさないため、メモリ効率が良いです。
- 欠点: 頻度が同じ異なるカテゴリが同じ値としてエンコードされるため、モデルがカテゴリを誤解する可能性があります。
5. 順序エンコーディング (Ordinal Encoding)¶
- 方法: カテゴリ変数が特定の順序(等級やグレード)を持つ場合、その順序に基づいて整数でエンコードします。たとえば、教育レベル「中学卒業」、「高校卒業」、「大学卒業」は順序エンコーディングで
[1, 2, 3]にエンコードできます。 - 利点: 順序情報を保持したままエンコードでき、モデルが順序を理解しやすくなります。
- 欠点: 順序のないカテゴリに使用すると、誤った関連性をモデルが学習してしまう可能性があります。
6. バイナリエンコーディング (Binary Encoding)¶
- 方法: カテゴリ変数をまず整数に変換し、その整数をバイナリ(2進数)で表現します。その後、各ビットを1つの列として展開します。例えば、カテゴリ
{A, B, C, D, E}にエンコードが必要な場合、Aが1(001)、Bが2(010)、Cが3(011)などとエンコードされます。 - 利点: ワンホットエンコーディングと比べて次元数が少なく、メモリ効率が良いです。また、特にカテゴリ数が多い場合に効果的です。
- 欠点: エンコード後のバイナリ列に直接的な解釈が難しいため、解釈可能性が低いことがあります。
選択のポイント¶
- 順序があるカテゴリ: 順序エンコーディングが適しています。
- 順序がないカテゴリ: ワンホットエンコーディングやターゲットエンコーディングが適しています。
- カテゴリ数が多い場合: ターゲットエンコーディングやバイナリエンコーディングが有効です。
1-3-2.競馬AIではどうすべきか?¶
主張¶
これといった正解は存在しないという大前提のもと、これまで分析してきた中でPyTorchを使うのであればカテゴリ特徴量は、基本的には次元埋め込みで対応すれば良いのではというのが現時点の結論です。
次元埋め込みとは、各カテゴリをベクトル空間に埋め込みことで、カテゴリが持つ定性的な特徴を数値として扱える手法です。
本質的には基本的なエンコーディング手法と考え方は同じです。
ただ、先に紹介した基本的な手法では、各カテゴリを区別するだけの変換しかできないため、そのカテゴリに対する解釈を学習モデルが汲み取れるわけではないという欠点があります。
そういった欠点に対応できうるのが、次元埋め込みの良いところだと考えます。
つまり、各カテゴリをベクトル化させることで、カテゴリ間の関係性も含めて学習させることができるのが、次元埋め込みの最大の特徴であると考えます。
一方で、基本的なエンコーディング手法は、入力値として数値的な区別をつけるための変換しかできないため、モデルはカテゴリ自体の特徴しか考えられません。
具体例¶
上記の主張を少しでも理解する助けになればと思い、これから具体例として全ての動物を学習モデルの入力に使いたい場合を考えてみましょう。
動物は何万単位と膨大な種類が地球上に存在しているため、基本的なやり方で素直にOne hot エンコーディングをしたりすると、膨大なベクトル空間が出来上がってしまい膨大な計算コストを要することになります。
そういった場合に、数万種類といる動物のカテゴリを数百次元のベクトル空間へ埋め込むことで、動物たちの特徴をとらえつつモデルの学習へ活かすことができるようになります。
どういうことかというと、例えば何かしらの学習タスクがある場合に、犬、猫、猿の3種類の動物におけるOne Hotエンコーディングと次元埋め込みの違いを見ていきたいと思います。
One-hot エンコーディングの場合¶
まずはOne Hotの場合、犬、猫、猿は以下のような各要素が1で長さが1の3次元のベクトルで表されます。
犬 = [1, 0, 0]
猫 = [0, 1, 0]
猿 = [0, 0, 1]
このとき、3つのOne Hotベクトルは、以下の3次元のベクトル空間の各軸上の点として表現されることになります。
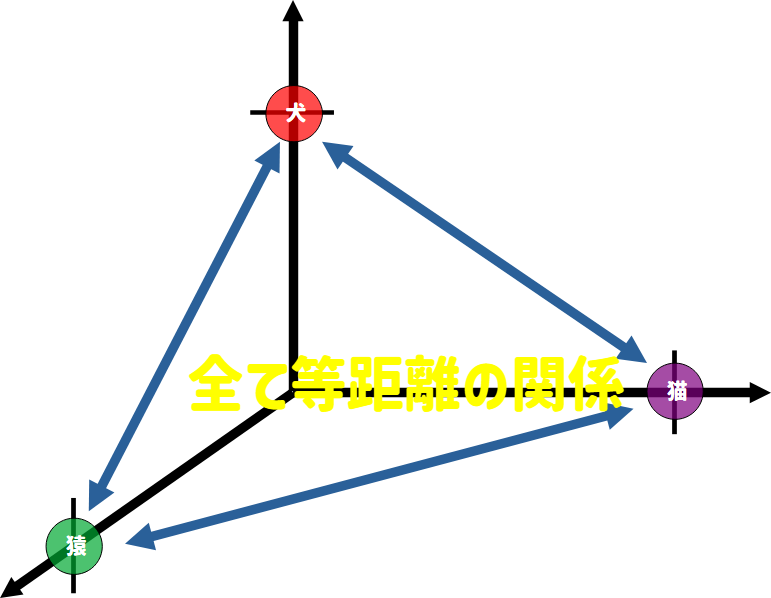
One Hotの場合この3つのベクトルが各入力値として扱われることになるのですが、モデルにとってこの3つのベクトルの位置関係というのはベクトル空間上で全て同じ距離にあるため、このような入力がされるとモデル側はこの3つのカテゴリを全て別々のものと区別して扱うようになります。
ベクトル埋め込みの場合¶
次にベクトル埋め込みの場合、犬、猫、猿を以下のような2次元のベクトル空間に埋め込むとします。
犬 = [0., 0.5]
猫 = [0.5, 0.]
猿 = [-0.3, 0.4]
このとき、3つのベクトルは以下の2次元のベクトル平面上の点として表現されることになります。
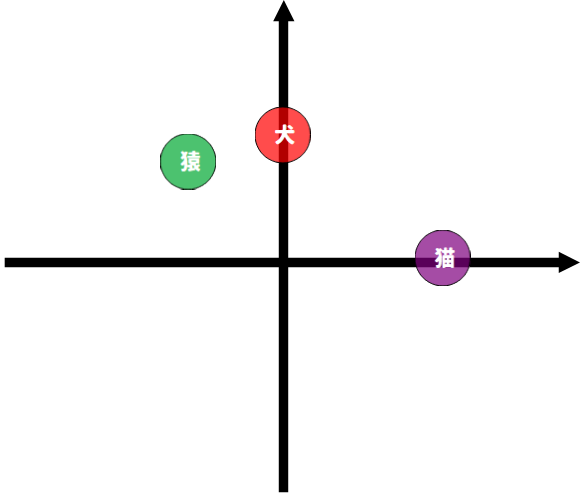
このとき、埋め込まれたベクトルは、モデルの学習を通して位置関係を学習していくようになります。
つまり、ベクトル埋め込みの最大の特徴は、モデルはこのベクトルへの埋め込み方を学習させることができることです
(ベクトル埋め込みだけして、位置関係を学習させない場合もありますが、あまり利点を感じないやり方だと思います。)
たとえば、4足歩行の動物かを分類するタスクの場合、モデルは学習を通して以下のようなベクトル埋め込みに変わっていくということです。
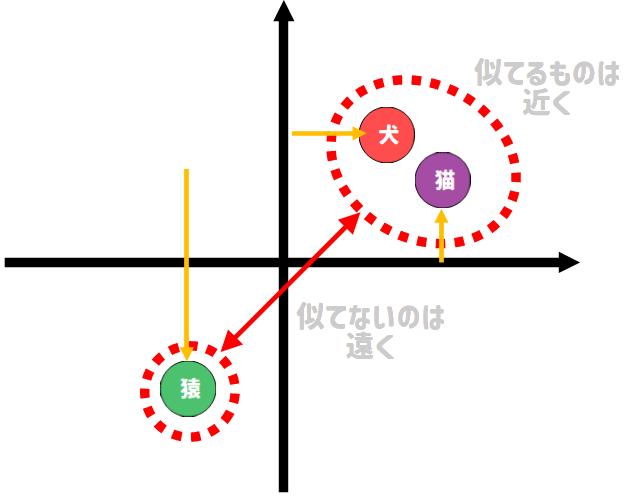
まとめ¶
なぜ位置関係を学習するかは、少し深い話が必要になってくるので割愛はしますが、ベクトル埋め込みの重要な考え方は、カテゴリ数よりも低次元のベクトル空間にカテゴリを埋め込むことで少ない情報で各カテゴリを表現しようとするところにあります。
要するに、カテゴリ同士のより抽象的な特徴を学び取ろうとすることで、ベクトル空間上で似ているカテゴリ同士の距離を近づけるように学ぶのが、ベクトル埋め込みの本質だと考えています。
1-3-3.実装はどうするのか?
PyTorchで実装する場合は、torch.nn.Embeddingというベクトル埋め込み用のレイヤー機能があるので、その機能を使うために各カテゴリ特徴量を調整するだけで問題ありません。
調整の仕方は、カテゴリに振り番{0,1,2,...,n}を割り振るだけで良いです。
つまり、{犬, 猫, 猿}とあれば、それぞれに{0, 1, 2}と割り振ることになります。
ただし、ここで注意すべきは、カテゴリの振り番を付ける場合、学習データと検証データとテストデータで、カテゴリの振り番に一貫性を持たせておく必要があります。
標準化と同じ考え方ですね。
つまり、学習データが持つカテゴリの集合とテストデータが持つカテゴリの集合に違いがあるとうまくいきません。
今回で言うと、競走馬の識別としてある馬IDが当てはまってます。
つまり、検証データやテストデータには新馬戦のレース情報が入っている場合があり、学習データには存在しない馬IDが存在します。
こうなってしまうと、モデルの学習等々で不都合が起きてしまいます。
この場合の対処法として代表的なのがすべてのデータをひっくるめてカテゴリに振り番を振る方法です。
こうすることで、テストデータにも番号を割り振ることができるので、学習や推論でベクトルへの埋め込みが出来ない問題は解決されます。
しかし、上記のようなやり方だと、本番運用する際に再度知らない要素が出てきた場合に推論が出来ない状態に陥ってしまいます。
なので、上記のやり方を採用するのは、カテゴリの種類が定常で運用後も増えることがない場合にのみ当てはまります。
では、馬IDなどの情報は捨てるべきかというとそうでもなくて、一応回避策はあります。
その方法が、分からないカテゴリの種類が出来てきた場合は、Unkownとして扱うカテゴリに割り振るようにすることです。
つまり、学習データで使われているカテゴリ数が100だった場合、カテゴリの割り振りとして{0, 1, 2, ..., 99}となりますが、そこに一つ追加のカテゴリ100番を追加します。
{0, 1, 2, ..., 99, 100}とすることで、検証データやテストデータで不明なカテゴリが出てきた場合は、それを全てカテゴリ100番として扱うようにすれば、運用でもカテゴリの一貫性を担保することができます。
それでは、カテゴリの前処理を行います。
# まずは、カテゴリ特徴量の種類を確認していきましょう。
category_list
# すべての期間でカテゴリ数が変わらない定常なもの
stationary_category = ["raceGrade", "place_en",
"field_en", "sex_en", "condition_en", "dist_cat_en"]
# カテゴリ数に変動があるもの
non_stationary_category = ["jockeyId", "teacherId", "horseId",
"stallionId", "breedId", "bStallionId", "b2StallionId"]
stationary_categoryは全て振り番が割り振られている状態なので、このままでOK
non_stationary_categoryを対象に処理を行う。
for key, dataset in dataset_mapping.items():
for cat in non_stationary_category:
cat_unique = dataset.train[cat].unique()
# カテゴリの振り番のマッピングを作成
cat_map = {c: n for n, c in enumerate(cat_unique)}
# 学習・検証・テストデータにマッピングを実施
dataset.train[cat+"_en"] = dataset.train[cat].map(cat_map)
dataset.valid[cat+"_en"] = dataset.valid[cat].map(cat_map)
dataset.test[cat+"_en"] = dataset.test[cat].map(cat_map)
# 割り振れなかったものを、Unkownのカテゴリとしてセット
dataset.valid[cat+"_en"].fillna(len(cat_map), inplace=True)
dataset.test[cat+"_en"].fillna(len(cat_map), inplace=True)
# データ型をintにしておく
dataset.train[cat+"_en"] = dataset.train[cat+"_en"].astype("int64")
dataset.valid[cat+"_en"] = dataset.valid[cat+"_en"].astype("int64")
dataset.test[cat+"_en"] = dataset.test[cat+"_en"].astype("int64")
for cat in stationary_category:
# データ型をintにしておく
dataset.train[cat] = dataset.train[cat].astype("int64")
dataset.valid[cat] = dataset.valid[cat].astype("int64")
dataset.test[cat] = dataset.test[cat].astype("int64")
以上でカテゴリエンコード処理は終わりです。
1-4.PyTorchで使うデータセット作成¶
これまで行った前処理ができたら、PyTorchで扱えるようにDatasetを作成してあげます。
LightGBMでいうlightgbm.Datasetと同じものです。
作り方は、もうほぼ公式ドキュメントと同じやり方になるので、実装例だけお見せします。
dataPreP.encoding_columns
# 特徴量のカラム名が変わったので再定義しておく
# 量的変数の特徴量
num_feas = [
'distance_dev',
'number_dev',
'boxNum_dev',
'odds_dev',
'favorite_dev',
'age_dev',
'jweight_dev',
'weight_dev',
'gl_dev',
'race_span_fill_dev',
] + ['winR_stallion', 'winR_breed', 'winR_bStallion', 'winR_b2Stallion']
# 質的変数の特徴量
cat_feas = [
'place_en',
'field_en',
'sex_en',
'condition_en',
'jockeyId_en',
'teacherId_en',
'dist_cat_en',
'horseId_en',
"raceGrade", "stallionId_en", "breedId_en", "bStallionId_en", "b2StallionId_en"
]
Dataset自体は、PyTorch標準のものを使ってもいいし、自作することもできるにはできます。
今回は、今後もことも考慮して自作したDatasetクラスを作ってみます。
の作り方のポイントは以下
Datasetクラスは、データセットのロード方法を定義するための基本クラスで、以下の3つのメソッドを備えています:
__init__: データセットの初期化__len__: データセットのサンプル数を返す__getitem__: 指定したインデックスに対応するデータとラベルを返す
また、今回のデータ前処理では、カテゴリエンコードをしているため、カテゴリ用の特徴量と数値用の特徴量で分けてDatasetを定義しておきます。
from torch.utils.data import Dataset
import torch
# Datasetクラスを継承してカスタムDatasetクラスを作成
class CustomKaibaAIDataset(Dataset):
def __init__(self, dfnum: pd.DataFrame, dfcat: pd.DataFrame, dflabel: pd.Series) -> None:
self.numerous = dfnum
self.cat = dfcat
self.label = dflabel
def __len__(self):
return len(self.label)
def __getitem__(self, index):
num_fea = torch.tensor(self.numerous.loc[index], dtype=torch.float32)
# カテゴリ特徴量は一つ一つベクトル埋め込み層に突っ込むので、特徴量ごとに分けてtensor化しておく
cat_feas = torch.tensor(
[self.cat[c].loc[index] for c in self.cat.columns], dtype=torch.float32)
label = torch.tensor(self.label[index], dtype=torch.float32)
return num_fea, cat_feas, label
dataset_mappingにPyTorchのDatasetをセット
for key, dataset in dataset_mapping.items():
# 教師データの作成:1着なら1でそれ以外なら0
dataset.train["object_label"] = dataset.train["label"].isin([
1]).astype(int)
dataset.train_dataset = CustomKaibaAIDataset(
dataset.train[num_feas],
dataset.train[cat_feas],
dataset.train["object_label"]
)
dataset.valid["object_label"] = dataset.valid["label"].isin([
1]).astype(int)
dataset.valid_dataset = CustomKaibaAIDataset(
dataset.valid[num_feas],
dataset.valid[cat_feas],
dataset.valid["object_label"]
)
dataset.test["object_label"] = dataset.test["label"].isin([1]).astype(int)
dataset.test_dataset = CustomKaibaAIDataset(
dataset.test[num_feas],
dataset.test[cat_feas],
dataset.test["object_label"]
)
# カテゴリの埋め込みを行うためにカテゴリ数を指定しておく
dataset.cat_num_list = [dataset.train[cat].nunique()+1 for cat in cat_feas]
今回の講座はここまでです。
次回続きから始められるように、作成したdataset_mappingを保存しておきましょう。
import pickle
cache_dir = pathlib.Path("./data")
with open(cache_dir / "dataset_mapping.pkl", "wb") as f:
pickle.dump(dataset_mapping, f)



コメント