はじめに¶
私は競馬予想AIの開発をしています。動画で制作過程の解説をしています。良ければ見ていってください。

また、共有するソースの一部は有料のものを使ってます。
同じように分析したい方は、以下の記事から入手ください。

3.血統ごとの成績とレース条件の取り扱い¶
前回までは血統の理解を深めるために基礎的な分析を中心に取り上げていたので、
今回はより収益に踏み込んだ分析を行っていく。
取り上げる内容は以下
- 過去数年間ごとに単勝・連対立・複勝率を分析
- 血統情報をモデルへ追加する方法
3-0.下準備¶
ソースの一部は有料のものを使ってます。
同じように分析したい方は、以下の記事から入手ください。
競馬予想AI 統合分析プログラムの記事
3-0-1.必要そうなものをインポート¶
from typing import Literal
import pathlib
import numpy as np
import warnings
import sys
import pandas as pd
sys.path.append("..")
from src.data_manager.preprocess_tools import DataPreProcessor # noqa
from src.data_manager.data_loader import DataLoader # noqa
from src.core.db.controller import execSQL, getTableList, getDataFrame # noqa
warnings.filterwarnings("ignore")
3-0-2.血統データをDBから取得¶
3-0-2-1.接続先DB情報¶
# 接続先DB (このnotebookの場所が「notebook」フォルダにあるので一つ上の階層に戻ってDBファイルパスを生成)
root = pathlib.Path(".").absolute().parent
dbpath = root / "data" / "keibadata.db"
3-0-2-2.DBから血統情報のテーブル一覧を取得¶
# 血統情報が入っているテーブルは「horseblood」という接頭辞がついたテーブルなので、その一覧を取得
horseblood_list = [tbl for tbl in getTableList(dbpath) if "horseblood" in tbl]
horseblood_list.sort(key=lambda x: int(x[-4:]))
3-0-2-3.テーブル一覧から5代血統情報をDataFrameに変換¶
# DBから取得:concatでhorseblood_listにあるテーブル情報のDataFrameをすべて結合する
dfblood = pd.concat(
[getDataFrame(tbl, dbpath) for tbl in horseblood_list], ignore_index=True)
3-0-3.2000年から2023年の出走情報を取得¶
3-0-3-1.ベース前処理の実行¶
今回より前回の結果から前処理としてレースのクラスと獲得賞金をグレードというカテゴリ変数に変換する処理を追加している。
前回記事↓
start_year = 2000
end_year = 2023
data_loader = DataLoader(start_year, end_year, dbpath=dbpath)
dataPreP = DataPreProcessor()
df = data_loader.load_racedata()
df = dataPreP.exec_pipeline(df)
以上で準備完了
3-0-4.パート1の内容: 種牡馬と繁殖牝馬の種牡馬情報を追加する¶
前回, 前々回の内容から出走情報に父と母父などその他の血統情報を追加する
def add_blood_info_to_df(
df: pd.DataFrame,
mode: Literal[
"s", "ss", "sb", "b", "bs", "bb",
"sss", "ssb", "sbs", "sbb", "bss", "bsb", "bbs", "bbb",
"ssss", "sssb", "ssbs", "ssbb", "sbss", "sbsb", "sbbs", "sbbb",
"bsss", "bssb", "bsbs", "bsbb", "bbss", "bbsb", "bbbs", "bbbb",
]
):
index_map = {
# region Stallion 1gen, 2gen 3gen
"s": (0, "stallion", "gen1"),
"ss": (0, "sStallion", "gen2"), "sb": (8, "sBreed", "gen2"),
"sss": (0, "s2Stallion", "gen3"), "ssb": (4, "s2Breed", "gen3"),
"sbs": (8, "sbStallion", "gen3"), "sbb": (12, "sbBreed", "gen3"),
# endregion
# region Stallion 4gen
"ssss": (0, "s3Stallion", "gen4"), "sssb": (2, "s3Breed", "gen4"),
"ssbs": (4, "s2bStallion", "gen4"), "ssbb": (6, "s2bBreed", "gen4"),
"sbss": (8, "sbsStallion", "gen4"), "sbsb": (10, "sbsBreed", "gen4"),
"sbbs": (12, "sb2Stallion", "gen4"), "sbbb": (14, "sb2Breed", "gen4"),
# endregion
# region Breed 1gen, 2gen 3gen
"b": (16, "breed", "gen1"),
"bs": (16, "bStallion", "gen2"), "bb": (24, "bBreed", "gen2"),
"bss": (16, "bsStallion", "gen3"), "bsb": (20, "bsBreed", "gen3"),
"bbs": (24, "b2Stallion", "gen3"), "bbb": (28, "b2Breed", "gen3"),
# endregion
# region Breed 4gen
"bsss": (16, "bs2Stallion", "gen4"), "bssb": (18, "bs2Breed", "gen4"),
"bsbs": (20, "bsbStallion", "gen4"), "bsbb": (22, "bsbBreed", "gen4"),
"bbss": (24, "b2sStallion", "gen4"), "bbsb": (26, "b2sBreed", "gen4"),
"bbbs": (28, "b3Stallion", "gen4"), "bbbb": (30, "b3Breed", "gen4"),
# endregion
}
idx, prefix, genCol = index_map[mode]
idf = dfblood.iloc[idx::32].reset_index(drop=True)
idf[genCol] = idf[genCol].str.split("\n", expand=True)[
0].str.replace("\n", "")
df[f"{prefix}Id"] = df["horseId"].map(
idf.set_index("horseId")[f"{genCol}ID"])
df[f"{prefix}Name"] = df["horseId"].map(idf.set_index("horseId")[genCol])
return df, idf[["horseId", genCol, f"{genCol}ID"]].rename(columns={genCol: "GenName", f"{genCol}ID": "GenID"})
df, dfstallion = add_blood_info_to_df(df, "s")
df, dfbreed = add_blood_info_to_df(df, "b")
df, dfbStallion = add_blood_info_to_df(df, "bs")
df, dfgen3 = add_blood_info_to_df(df, "bbs")
df, dfgen3 = add_blood_info_to_df(df, "bbbs")
df[["horseId", "stallionId", "stallionName", "bStallionId",
"bStallionName", "b2StallionId", "b2StallionName"]]
以上で前回までで分析した情報の追加完了
3-1.血統と入賞の関係¶
血統とはもともと強い優秀な親の血を受け継いできた証のこと。
思うに強いや優秀の基準は不明確だと考えていて、十分な成果は残せずとも番いの欠点を補完できる馬であったり、
G1などの重賞クラスで勝利しているなど様々な理由で、馬主がその馬を良いと考え交配が行われてきたと考えられる。
つまり、馬主たちは考え得る最高の組合せで能力の高い競走馬を育てたいという願望(前提)があることから、
全ての競走馬は能力の高い馬になることを期待されて生まれてきていると考えて良い。
つまり、その血統の組み合わせには意図があり、強い馬を生み出すための規則性が存在している可能性が高いと考える。
しかし、今持っている情報や分析結果だけではまだ深堀出来るほどの知見はないので、
今回は簡単に父と母または父と母父の組み合わせから競走馬の入賞の関係を紐解いていく
3-1-0.分析手順¶
- 父×母または父×母父の組み合わせでグループ化と統計(どちらの組み合わせを採用するか決定)
- 採用した組合せで産駒の単勝・連帯・複勝率を算出
- 算出結果を確認し、簡単なシミュレーションを行う
3-1-1.父×母または父×母父の組み合わせでグループ化と統計¶
まずはそれぞれの組合せのグループを作る
# 父×母のグループ
sb_columns = ["stallionId", "breedId", "stallionName", "breedName"]
dfSBg = pd.merge(
dfstallion[["horseId", "GenID", "GenName"]].rename(
columns={"GenID": "stallionId", "GenName": "stallionName"}),
dfbreed[["horseId", "GenID", "GenName"]].rename(
columns={"GenID": "breedId", "GenName": "breedName"}),
on="horseId"
).groupby(sb_columns)
# 父×母父のグループ
sbs_columns = ["stallionId", "bStallionId", "stallionName", "bStallionName"]
dfSBSg = pd.merge(
dfstallion[["horseId", "GenID", "GenName"]].rename(
columns={"GenID": "stallionId", "GenName": "stallionName"}),
dfbStallion[["horseId", "GenID", "GenName"]].rename(
columns={"GenID": "bStallionId", "GenName": "bStallionName"}),
on="horseId"
).groupby(sbs_columns)
統計を出す
# 父×母の統計
dfSBg[sb_columns].value_counts().sort_values().describe().to_frame().T
# 産駒数上位10組を出す
dfSBg[sb_columns].value_counts().sort_values().tail(10).to_frame().T
# 父×母父の統計
dfSBSg[sbs_columns].value_counts().sort_values().describe().to_frame().T
# 産駒数上位10組を出す
dfSBSg[sbs_columns].value_counts().sort_values().tail(10).to_frame().T
分かり切ってはいたが、父×母より父×母父の方が偏りは激しいが組合せに対するサンプル数は各段に多いことが分かる。
よって、前々回の話からも父系の情報でみるべきという結果から、父×母父の組み合わせを採用する
もう少し深堀…¶
もう少し産駒数について突いてみる
単純にどのタイミングで産駒数が激増するのか確認してみる
idf: pd.DataFrame = dfSBSg[sbs_columns].value_counts().reset_index(
).set_index(sbs_columns[2:])[["count"]].sort_values("count")
idf
とりあえず、75%分位以降で1%分位ずつ値を見ていく
idf["count"].quantile(np.arange(0.75, 1.0, 0.01)).to_frame().T
まさかの99%分位ですら16頭の産駒しかいない。。。
さらに詳しく、99%分位以降0.0005%分位ずつ見ていく
idf["count"].quantile(np.arange(0.99, 1.0, 0.0005)).to_frame().T
更に99.9%分位ですら100頭にも到達しないのは、凄まじい偏りぐあい
逆にこれだけ偏りがあるってことは、人気の組み合わせであったりなどの意図が隠れているのではないかと考えられる
どこまでを分析対象とするか¶
どういう調べ方をするかではあるんだけど、絞り込むための考え方として、
① ある程度実績のある産駒がいて
② 出走回数が平均的に走っている産駒がいて、
③ 出走情報のDataFrameで分析可能な産駒であること
としたい。
というのも、全体の出走情報で集計したときに競走馬が中央競馬で出走する回数の中央値が6回だったので、
半数が6回も走らないことから、それ以上を走っている競走馬の実力を見るのが妥当であるのと、
1頭当たりの出走回数のサンプル数を確保するのが狙い。
あとは、G1勝利した産駒がいることは、それだけ強い産駒を輩出できる可能性がある組合せであるので、
G1勝利した産駒がいる組み合わせにだけ絞り込む
ここでは2000年から2023年までのG1を1回以上制覇した競走馬で
かつ 出走回数が6回以上の競走馬で
かつ 1998年以降に生まれた競走馬について
父×母父の組み合わせに該当する組み合わせを採用する
# というわけでG1勝利馬だけのデータに絞り込む
dfhcnt = df.groupby("horseId")["horseId"].value_counts()
horseIdList = dfhcnt[dfhcnt >= 6].index.tolist()
df["birthH"] = df["horseId"].str[:4].astype(int)
dfG1 = df[df["raceGrade"].isin([8]) & df["label"].isin([1]) & df["horseId"].isin(
horseIdList) & (df["birthH"] > 1997)][sbs_columns[2:]].drop_duplicates(sbs_columns[2:])
dfG1.T
絞り込んだもので産駒数を確認
idfG1 = idf.loc[dfG1.values.tolist()]
idfG1.loc["All", "count"] = idfG1["count"].sum()
idfG1.sort_values("count").T
上手くいってそうなので、これで分析を進める
意外と対象の産駒が1頭だけにもかかわらずG1勝利している競走馬もいるようだ
3-1-2.採用した組合せで産駒の単勝・連帯・複勝率を算出¶
この分析の意義は、前節で絞り込んだG1勝利した産駒がいる血統の組み合わせに対して、
他の産駒についてもどのくらいの能力を見込めるのかを評価できると考えてのことである
つまり、G1勝利した産駒がいたがその血統の組み合わせが100頭いてそのうち1頭だけG1勝利できた場合と、
50頭いて10頭がG1勝利できた場合とでは、その組み合わせに対する期待が大きく変わってくる
そのため、G1勝利できた血統の組み合わせについて、単勝・連帯・複勝率を算出することで、
勝負強さだったりの好成績を残せる産駒を輩出できるかどうかを知ることが出来ると考えている
算出関数の作成¶
# inLabelで指定した着順に対して、target_columnsで指定した血統の組み合わせでdfGを集計する
# 集計方法は2種類で各産駒の平均値かカウント数を選択できる
def calcurate_winrate_by_blood(
dfG: pd.DataFrame,
inLabel: list[int],
target_columns=["stallionName", "bStallionName"]
) -> tuple[pd.DataFrame]:
dfG["win"] = dfG["label"].isin(inLabel).astype(int)
dflist = []
dflist2 = []
idf: pd.DataFrame = dfG.groupby(
target_columns+["horseId"])["win"].mean().rename("winrate").to_frame()
dflist += [idf.reset_index(level=len(target_columns))]
idf: pd.DataFrame = dfG.groupby(
target_columns+["horseId"])["win"].sum().rename("wincount").to_frame()
dflist += [idf.droplevel(level=len(target_columns)), dfG.groupby(
target_columns+["horseId"])["win"].count().rename("racecount").droplevel(level=len(target_columns))]
idf = idf.reset_index().groupby(target_columns)["wincount"]
dflist2 += [(idf.sum()/dfG.groupby(target_columns)
["win"].count()).rename("winrate").to_frame()]
idf: pd.DataFrame = dfG.groupby(
target_columns+["horseId"])["win"].sum().rename("wincount").to_frame()
dflist2 += [idf.reset_index().groupby(target_columns)["wincount"].sum().sort_values().to_frame(),
dfG.groupby(target_columns)["win"].count().rename("racecount")]
return pd.concat(dflist, axis=1), pd.concat(dflist2, axis=1)
単勝率を出してみる¶
dfG = df.copy()
dfG = dfG.set_index(sbs_columns[2:]).loc[idfG1.index.tolist()[
:-1]].reset_index()
idf1, idf1_des = calcurate_winrate_by_blood(dfG, [1])
idf1
簡単に統計を出してみる
# 産駒ごとの成績
idf1.describe().T
結果から産駒の単勝率は平均8%程度で、G1勝利馬を出したとてその他の産駒が強いという訳でもなさそうである。
というか中央値で見ると単勝率・単勝回数ともに0であることから、産駒の良しあしもかなりあることが分かる。
連対率を出してみる¶
idf2, idf2_des = calcurate_winrate_by_blood(dfG, [1, 2])
# 産駒ごとの成績
idf2.describe().T
結果から産駒の連対率は平均15%程度で、中央値で見ても11%とそれなりに善戦しているように見える。
血統が良いとそれだけ馬券に絡める素質があるのだと考えられそう。
とはいえ、4分の1は全く連対にも入れないようなので、参考程度の範疇になるだろうか・・・
複勝率を出してみる¶
idf3, idf3_des = calcurate_winrate_by_blood(dfG, [1, 2, 3])
# 産駒ごとの成績
idf3.describe().T
連対率と大きく変わらない結果である
特徴的な結果でない以上考察は割愛
3-2.簡単にルールベースで回収率のシミュレーション¶
血統からその産駒が勝てる勝てないの特徴を割り出すのは結構難しい。
というか、血統だけをみて勝てる馬を見分ける人なんてほとんどいないのではとも思う。
ほとんどは、他の競走馬との兼合いによるレース展開だとか、
騎乗する騎手やレース条件との相性だとかを過去の成績から考え、
その馬の基礎値を見るという意味合いで血統を考慮するのではないかと思う
なので、血統だけを見てその馬が走れるかそうでないかを判断するのは、新馬戦までを対象とすることにする
3-2-1.シミュレーションの条件¶
- 1. 扱うデータ
- 新馬戦を対象
- 2. 評価方法
- 年度別にレース条件ごとの単勝収益を見る
- 3. 産駒の勝率計算方法
- 対象の年度に対して過去15年間の産駒の新馬戦の成績を使って予測する
- 4. ベットする条件(ルール;規則)
- ① 十分に産駒の出走回数に実績がある(
racecountが10以上にあてはまる)こと - ②
血統の産駒の勝率が最も高いものを選択(同率の場合はどちらも選択) - 5. シミュレーション期間
- 予測対象期間は2019年から2023年とする
3-2-2.産駒の成績で単勝を賭けた場合の結果を集計する関数を定義¶
def calcurate_betperformance_by_blood(start=2019, end=2023):
span = 15
target_blood_cross = ["stallionId", "bStallionId"]
dflist, dflist2 = [], []
for bet_year in range(start, end+1):
target_year_list = list(range(bet_year-span, bet_year))
# 集計対象のレースに絞り込み、過去出走分も考慮する
horseIdList = df[df["raceDate"].dt.year.isin(
target_year_list)]["horseId"].unique()
idf = df[df["horseId"].isin(horseIdList) & (
df["raceDate"].dt.year < bet_year)]
_, idfdes = calcurate_winrate_by_blood(
idf[idf["raceDetail"].str.contains(r"新馬", regex=True)], [1], target_blood_cross)
# 予測対象データ
dftarget = df[
# 予測対象年
df["raceDate"].dt.year.isin([bet_year]) &
# 新馬戦のみ
df["raceDetail"].str.contains(r"新馬", regex=1)
].set_index(target_blood_cross)
# 父×母父の組み合わせの勝率のデータを追加
dftarget["winrate"] = idfdes["winrate"]
# 父×母父の組み合わせの合計出走数のデータを追加
dftarget["racecount"] = idfdes["racecount"]
dftarget = dftarget.reset_index(
)[dftarget.columns.tolist() + target_blood_cross]
# レース条件ごとに集計
for g, idfg in dftarget.groupby(["field", "dist_cat"]):
# ベット条件を追加
# ①の条件
idfg["bet"] = idfg["racecount"] > 9
# ②の条件
idfg["bet"] = idfg[idfg["bet"]].groupby(
"raceId")["winrate"].rank() < 2
# ①かつ②でないものを全てFalseにする
idfg["bet"].fillna(False, inplace=True)
dflist2 += [idfg]
# 単勝に賭けた場合の成績を算出
# 収益
profit = idfg[idfg["bet"] &
idfg["label"].isin([1])]["odds"].sum()*100
# 的中率
hitRate = (
(idfg[idfg["bet"]]["label"].isin([1])).mean()*100).round(1)
# 的中数
hitNum = (idfg["bet"] & idfg["label"].isin([1])).sum()
# ベット回数
betNum = max(1, idfg["bet"].sum())
# ベット率
betRate = (100*idfg["bet"].mean()).round(1)
dflist += [
pd.DataFrame(
list(g)+[int(profit),
f"{round(profit/betNum, 1)}%", hitNum, f"{hitRate}%", betNum, f"{betRate}%"],
index=["馬場", "距離カテゴリ", "収益", "回収率", "的中数", "的中率", "ベット回数", "ベット率"],
columns=[bet_year]
).T
]
dfsummary = pd.concat(dflist).reset_index(names="年度").set_index(
["馬場", "距離カテゴリ", "年度"]).sort_index()
return dfsummary, pd.concat(dflist2, ignore_index=True).sort_values(["raceDate", "raceId", "number"])
3-2-3.集計の実行と結果の確認¶
dfsummary, dfbet = calcurate_betperformance_by_blood()
dfsg = dfsummary.reset_index().groupby(["馬場", "距離カテゴリ"])
(dfsg["収益"].sum()/dfsg["ベット回数"].sum()
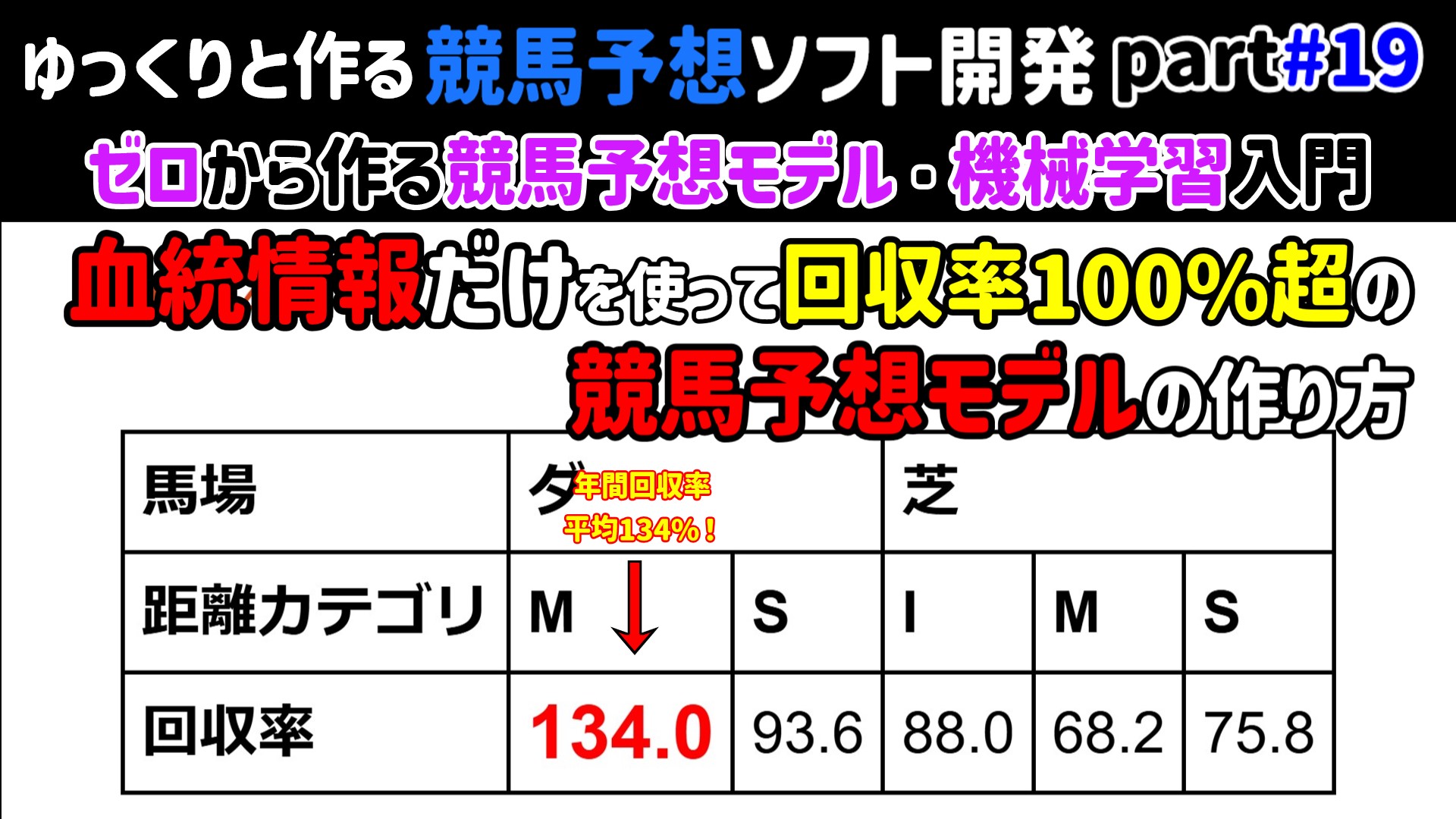
).astype(float).round(1).rename("回収率").to_frame().T
かなり泥臭く行った
全体の集計結果をみるとダートのマイル距離で回収率が130%を超えている
3-2-4.ダートのマイル距離の年度別結果を見てみる¶
dfsummary.loc[("ダ", "M")]
上記の結果を見るに、ほとんどの年度で回収率100%を超えられている
しかし、2020年以降は年度を追うごとに回収率が下がっていることが見て取れる。
とはいえベット回数と的中回数が少ないというのもあり、再現性の高いやり方かと言われるとそうでもないのが瑕
3-2-5.裏にありそうな原因を考えてみる¶
単純にサンプル数が少ないので、すべての結果がたまたまであるとも言えるが、
敢えて理由を作るのであれば、2個ぐらい考えられて
1つ目が、2019年のダートのマイルは全く稼げておらず、
血統の勝率をみる戦法は注目されてなかったが2020年で回収率が241%と2倍のリターンが来るという結果から、
多くの競馬予想家が目を付け出し、オッズの低下でアルファを取れなくなってきたのだろうと。
- Tip:
- なぜなら、この集計方法は血統ごとの勝率だけを見ているからで、
- これはExcelなどの表計算ソフトさえあれば簡単に割り出せることから、
- 3年の間にバレてしまって利益が出せなくなったと考えられるからである。
2つ目が、年度ごとにデビューする新馬たちの種牡馬や繫殖牝馬の親たちに大きな変化がこの3年間で起きたことで、
2020年から2022年までにデビューした新馬たちを産んだ親たちにたまたま過去の血統と似たような特徴が出ており、
2023年以降の新馬を産んだ親には過去の血統ごとの勝率の関係が当てはまらなくなってしまったのではないかと考えられる。
- Tip:
- この2つ目の仮説が正しいのであれば、その血統の流れみたいなものが
- 特定の期間で繰り返されている可能性があることを示唆しているとも考えられる。
- この仮説の簡単な確認方法としては、
- 先の分析の対象期間を2008年ぐらいから長めにとって調べてみて回収率の変遷を見ると良い
どことなく2つ目の方は深堀しても良いように思う。
別の機会があれば取り上げることとする
- Tip:
- 実際にディープインパクトが種牡馬に移行した2012年からその産駒が出てきた2015年の新馬戦で見ると、
- ディープインパクト産駒の新馬が軒並み1番人気となっていた。
- 中にはそのような産駒が過度に人気していて、去年まで好成績していた産駒の人気が薄くなった影響で、
- 収益が伸びるというのは可能性としてあり得そうであるため深堀する価値はありそう。
3-2-6.最後にダートのマイルでどの人気に賭けていたのか確認¶
dfbet["year"] = dfbet["raceDate"].dt.year
idfbet = dfbet[dfbet["field"].isin(
["ダ"]) & dfbet["dist_cat"].isin(["M"]) & dfbet["bet"]]
dflist = []
for year, idfbg in idfbet.groupby("year"):
dflist += [idfbg["favorite"].value_counts().rename(year).sort_index().to_frame().T]
print("人気別ベット回数分布")
display(pd.concat(dflist).fillna(0).convert_dtypes().T.sort_index().T)
idfbet2 = dfbet[dfbet["field"].isin(
["ダ"]) & dfbet["dist_cat"].isin(["M"]) & dfbet["bet"] & dfbet["label"].isin([1])]
dflist = []
for year, idfbg in idfbet2.groupby("year"):
dflist += [idfbg["favorite"].value_counts().rename(year).sort_index().to_frame().T]
print("人気別的中回数分布")
display(pd.concat(dflist).fillna(0).convert_dtypes().T.sort_index().T)
結果を見るに結構漫勉なく色んな人気にベットしていることが分かる
的中したものをみると、10番人気や15番人気を当てているなどかなり尖った結果をしている
3-2-7.10番人気を当てているレースを見てみる¶
display_columns = ["raceId", "place", "field", "distance", "weather", "condition", "number", "label", "favorite",
"odds", "horseName", "stallionName", "bStallionName", "b2StallionName"]
# 実際に10番人気以降にベットして的中したレースに絞り込み
idfbet2 = idfbet2[idfbet2["favorite"].isin([10])]
target_raceId_list = idfbet2["raceId"].unique()
idfbet2[display_columns]
母父にフジキセキが、父にヘニーヒューズがいる
他にどういった馬が出走していたのか確認
# 10番人気を当てた最近のレースを見てみる
idf10 = df[df["raceId"].isin([target_raceId_list[-1]])]
idf10[display_columns].sort_values("favorite")
結果からちらほら見たことのある血統がいるように見える。
産駒の勝率を出してみる
_, idfdes = calcurate_winrate_by_blood(df[df["raceDate"].dt.year.isin(list(
range(2022-15, 2022))) & df["raceDetail"].str.contains(r"新馬", regex=True)], [1])
さっきの10番人気を当てたレース情報に加える(産駒の勝率データがない場合は削除)
idfs = pd.merge(idf10, idfdes.reset_index(), on=[
"stallionName", "bStallionName"], how="inner")[display_columns[:-3]+["winrate", "racecount"]].sort_values("favorite")
pd.merge(idfs, idfbet[["raceId", "horseName", "bet"]],
on=["raceId", "horseName"], how="left")
というわけで、蓋を開けるとたまたまベット条件に当てはまっていただけであるというのは否めない結果である。
とはいえ、他の競馬予想モデルとの違いは、ベットする条件がルールベースで行われていることである。
つまり、その馬を選択した理由を明確に答えられるのがルールベースの良いところである。
しかし、その一方で人が考え出せるルール(今回でいう勝率が一番高い競走馬に賭けるなど(1))には限界があり、
そのルールを採用する意図((1)の意図はなるべく勝てる馬を選ぶためだとか)が明確で単純になりがちなため、
すぐにオッズに対する割安感がなくなる可能性が高いと思われる(=その結果回収率が安定しない)
3-3.一旦まとめ¶
3-3-1.分かったこと¶
血統と入賞の関係を見て分かるように、
血統だけではその馬が将来勝てる馬になるかは実際に出走してみないと分からないのだろうと考える。(自明ではある)
しかし、回収率の分析結果で見るに一部のダートのレース条件で極端に勝てていることから、
芝とダートでは前提が大きく違っている可能性があるように思う
もしくは、芝で大活躍していた親の産駒がダートに出走した際に過度に人気が集まっているとかで、
ダートに強い血統の競走馬が低く評価され、結果高い回収率につながっていたのかもしれない。
3-3-2.次回やること¶
2つの決定事項を決めるために以下の目的でモデルを作成する
- 確認したいこと
- 1. 芝とダート問題
- これまでの分析で芝とダートでは血統の段階から大きく性質が違うように見える
- 初期のころの簡易分析でも芝とダートでは馬場状態が与える影響から違うことも分かっている
- そのため、芝とダートでテストデータを分けるべきではと考え検証したいのが動機
- 2. 血統どこまで入れれば良いか問題
- 血統の父と母父のみ取り上げて3回にわたって分析してきた
- 産駒数や成長度合い、回収率と様々な切り口で血統を味見した結果、
- 血統だけの情報でも一部の条件で高い回収率を見込めることが分かったので、
- 血統の情報は入れるべきなのは自明である
- 問題はどこまでの情報を考慮すべきかであるが、
- これといった解決が思い浮かばないので検証したいのが動機


コメント